





MCU, MPU lub FPGA: które rozwiązanie jest najlepsze w zastosowaniu sztucznej inteligencji (AI) w urządzeniach brzegowych?
Zaawansowane rozwiązania z zastosowaniem sztucznej inteligencji (AI), takie jak pojazdy autonomiczne, muszą podejmować kluczowe dla bezpieczeństwa decyzje w ciągu nanosekund, nie mogąc dopuścić do błędu. Życie osób przebywających w pojeździe autonomicznym, a także innych użytkowników dróg, zależy od zdolności wysokowydajnych procesorów graficznych (GPU) i złożonych algorytmów sieci neuronowej do rozpoznawania w czasie rzeczywistym obiektów, takich jak piesi, rowerzyści, sygnalizacja świetlna i droga znaki ostrzegawcze.

Nie tylko pojazdy autonomiczne wykorzystują najbardziej wyspecjalizowany sprzęt do obsługi matematycznie złożonych modeli sieci neuronowych. Najbardziej znane przykłady wykorzystania sztucznej inteligencji w praktyce (np. zautomatyzowana internetowa obsługa klienta, tzw. „chatbot” obsługiwana przez platformę Watson firmy IBM) działają na serwerach zawierających układy ultra-wydajnych procesorów.
Nie oznacza to jednak, że wszystkie implementacje sztucznej inteligencji wymagają najszybszego i najmocniejszego silnika przetwarzania. W rzeczywistości zasada, której należy przestrzegać, to ta, którą zawsze stosowali programiści: wymagania funkcjonalne rozwiązania powinny określić specyfikacje sprzętu, nie odwrotnie. Nadmierne specyfikowanie sprzętu w dziedzinie sztucznej inteligencji nie jest bardziej właściwe ani sensowne, niż w jakiejkolwiek innej dziedzinie przetwarzania wbudowanego.
Zaskakujące jest to, ile systemów AI może działać całkowicie niezależnie od usług przetwarzania w chmurze, na tanich platformach sprzętowych, takich jak 32-bitowy mikrokontroler lub układ FPGA o średniej gęstości upakowania.
Zalety edge computingu
Oczywiście programiści aplikacji AI mogą wybrać przetwarzanie w chmurze, gdzie zasoby sprzętowe nie są w żaden sposób ograniczone. Jest to architektura stosowana na przykład przez usługę głosową Alexa firmy Amazon: urządzenie takie jak inteligentny głośnik „słyszy” użytkownika wypowiadającego słowo „Alexa”, a następnie łączy się z usługą chmurową rozpoznawania mowy, aby zinterpretować wypowiadaną komendę. Często istnieją jednak dobre powody ku temu, aby systemy wbudowane wnioskowały lokalnie, na urządzeniach brzegowych.
- Gdy połączenie sieciowe działa wolno, może powodować duże opóźnienia. Jeśli połączenie sieciowe zostanie zerwane, funkcja wnioskowania zawodzi całkowicie. Lokalne wnioskowanie eliminuje tę przyczynę zawodności.
- Wnioskowanie sztucznej inteligencji wymaga przesłania dużej ilości danych, a niektórzy dostawcy usług sieciowych pobierają wysokie opłaty za tego typu transmisję
- Połączenie sieciowe jest krytycznym punktem podatności na ataki złośliwego oprogramowania innych zagrożeń. Samodzielne urządzenie przeprowadzające wnioskowanie zabezpiecza przed atakami sieciowymi.
- Wnioskowanie w chmurze wymaga znacznej infrastruktury, w tym sprzętu sieciowego, usług sieciowych i usług w chmurze. Urządzenie OEM eliminuje potrzebę specyfikacji i utrzymywania tej infrastruktury poprzez wnioskowanie „na krawędzi” sieci.
Istnieją więc ważne powody przemawiające za stosowaniem lokalnego wnioskowania na urządzeniach takich jak mikrokontrolery, procesory i układy FPGA. Ale czy wybrana przez programistę platforma sprzętowa wpływa na rodzaj rozwiązania AI, który będą w stanie skutecznie wdrożyć?
Odpowiedź
Istnieją dwa ważne parametry, które określają wymagania sprzętowe w projekcie wbudowanego AI, tak jak pokazano na Rysunku 1:
- Prędkość (lub opóźnienie)
- Precyzja
Ogólnie mówiąc, im więcej czasu ma twój system, by podjąć decyzję na podstawie danych wejściowych, i im wyższa jest twoja tolerancja na błędy, tym słabszy może być twój sprzęt. System wykrywania obiektów w autonomicznym pojeździe znajduje się na skrajnym końcu spektrum przypadków użycia, wymagając zarówno opóźnienia na poziomie nanosekund, jak i niemal 100% dokładności.
 Rysunek 1. Szybkość i dokładność określają wymagania sprzętowe dla AI
Rysunek 1. Szybkość i dokładność określają wymagania sprzętowe dla AI
Dla porównania, rozważmy inteligentną klapę dla kota, która odblokowuje się tylko dla pupila, natomiast blokuje przejście wszystkim innym zwierzętom, niezależnie od gatunku. Dobrze byłoby, aby temu urządzeniu zajęło do 500 ms na przetworzenie sygnału wejściowego z kamery zamontowanej na zewnątrz klapy dla kota. Właściciele zwierząt mogą zaakceptować dokładność 98%, gdzie raz na 50 przypadków zwierzę nie jest wpuszczane przy pierwszej próbie, a zatem program rozpoznawania uruchamia się po raz drugi. Możliwe byłoby zmniejszenie opóźnienia do 10 ms i zwiększenie jej dokładności działania do 99%, ale to wiąże się ze znacznymi dodatkowymi kosztami. Pytanie do programisty brzmi: czy poprawa wydajności będzie miała jakikolwiek wpływ na wartość, jaką czerpie z produktu konsument?
To naprawdę niezwykłe, ile pracy AI może wykonać przy nawet niewielkiej ilości sprzętu. Rysunek 2 sugeruje, że minimalne wymagania sprzętowe dla AI to 32-bitowy MCU oparty na Arm Cortex-M. W rzeczywistości STMicroelectronics znalazł sposób na wdrożenie AI bez konieczności stosowania MCU. ST umieścił bowiem mały blok obliczeniowy o nazwie Machine Learning Core (MLC) w niektórych czujnikach ruchu MEMS, m.in. w akcelerometrze/żyroskopie LSM6DSOX. Czujnik ten może być wykorzystywany do zbierania danych o rodzaju ruchu, takiego jak bieganie, chodzenie, siedzenie lub jazda. Cechy tych danych, takie jak średnia, wariancja, energia i wartości międzyszczytowe, są analizowane offline, aby stworzyć rodzaj algorytmu wykrywania zwanego drzewem decyzyjnym.
Jeśli LSM6DSOX jest osadzony, na przykład, w sportowej opasce na nadgarstek, jego MLC jest w stanie zastosować drzewo decyzyjne w czasie rzeczywistym do wykonywanych pomiarów ruchu i sklasyfikować aktywność użytkownika. QuickLogic, producent programowalnego System-on-Chip (SoC), stosuje podobne podejście, aby umożliwić zaawansowane aplikacje konserwacji prognozowanej na niedrogich urządzeniach, takich jak platforma QuickAITM lub MCU oparte na Arm Cortex-M4.
Konserwacja prognozowana zależy od rozpoznania różnych rodzajów danych szeregów czasowych, takich jak wibracje i dźwięk. Głębokie uczenie się i sieci neuronowe są powszechnie stosowane do wykrywania wskaźników błędów we wzorach tych szeregów czasowych. Algorytmy te są podzbiorem szerszego zestawu algorytmów zwanych klasyfikatorami. Klasyfikatory przekształcają dostępne dane wejściowe w pożądane dyskretne klasyfikacje wyników poprzez wnioskowanie, pojęcie obejmujące szeroki zakres metod.
Zestaw narzędzi programistycznych SensiML AI firmy QuickLogic zapewnia kompletne środowisko do budowania inteligentnych punktów końcowych IoT przy użyciu najbardziej odpowiednich technik uczenia maszynowego, patrz: Rysunek 2.
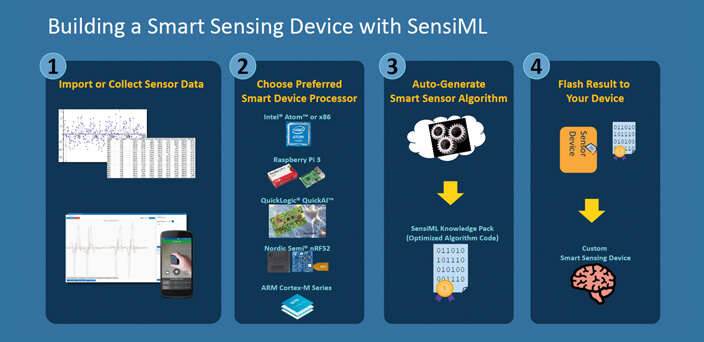 Rysunek 2. Przebieg rozwoju aplikacji uczenia maszynowego przy użyciu zestawu narzędzi QuickLogic SensiML AI
Rysunek 2. Przebieg rozwoju aplikacji uczenia maszynowego przy użyciu zestawu narzędzi QuickLogic SensiML AI
Zbiór technik obejmuje przechwytywanie i etykietowanie nieprzetworzonych danych z czujników, analizę zestawu danych w celu uzyskania najbardziej wydajnego algorytmu spełniającego ograniczenia projektowe oraz automatyczne generowanie kodu od akwizycji sygnału do wyjścia klasyfikatora.
Proces ten jest zoptymalizowany dla docelowego sprzętu, takiego jak QuickAI lub inne obsługiwane platformy.
 Rysunek 3. Wnioskowanie w sieci neuronowej obejmuje miliony obliczeń matematycznych wykonywanych z dużą prędkością
Rysunek 3. Wnioskowanie w sieci neuronowej obejmuje miliony obliczeń matematycznych wykonywanych z dużą prędkością
Niektóre aplikacje AI mogą więc działać na bardzo ograniczonym sprzęcie o niskiej mocy. Niestety, nie wszystkie. Na przykład rozpoznawanie obrazów i wykrywanie obiektów wymaga sieci neuronowej, a przeprowadzanie lokalnego wnioskowania o wyuczonym modelu sieci neuronowej wymaga więcej mocy obliczeniowej niż uruchomienie drzewa decyzyjnego. Microchip Technology, dzięki wysokowydajnej rodzinie układów FPGA PolarFire o średnim stopniu integracji, dowodzi, że układy FPGA są z natury bardziej wydajne i szybsze w przeprowadzaniu lokalnego wnioskowania algorytmów sieci neuronowej niż inne urządzenia cyfrowe. Jak każdy układ FPGA, urządzenia PolarFire z natury obsługują przetwarzanie równoległe, a nie przetwarzanie sekwencyjne wykonywane przez mikrokontroler lub procesor aplikacyjny. PolarFire FPGA zapewniają również wydajność w obliczeniach DSP dzięki 8-bitowym blokom matematycznym. Na przykład układ PolarFire MPF500T zawiera 1480 takich bloków.
Jak pokazano na Rysunku 3, zdarzenie wnioskowania w sieci neuronowej zasadniczo obejmuje ogromną liczbę obliczeń wykonywanych równolegle. Testy firmy Microchip pokazują, że MPF300 PolarFire może uruchomić otwarty algorytm rozpoznawania obrazu TinyYolo v2, aby wykrywać zwierzęta, takie jak krowy i konie, z częstotliwością 43 klatek/s, zużywając mniej niż 3 W mocy.
Świadczy to o wydajności, z jaką PolarFire lokalnie implementuje algorytmy sieci neuronowej. W przypadku najbardziej zaawansowanych form wbudowanej sztucznej inteligencji, takich jak sterowanie głosem, rozpoznawanie twarzy i monitorowanie stanu maszyny – zarówno NXP, jak i ST zapewniają kompleksową ofertę sprzętu i oprogramowania, od mikrokontrolerów opartych na Arm Cortex-M po procesory aplikacyjne: STM32MP1 od ST posiada dwa rdzenie procesorów Arm Cortex-A7, a NXP oferuje szeroką gamę procesorów z serii i.MX opartych na rdzeniach Arm Cortex-A. Obaj producenci wspierają te oferty sprzętowe za pomocą narzędzi AI i narzędzi programistycznych. NXP zapewnia nawet wzorcowe projekty „pod klucz”, które pokazują, że aplikacje takie jak lokalne sterowanie głosem, wykrywanie anomalii i rozpoznawanie twarzy można wykonywać na serii procesorów i.MX RT – urządzeniach wyposażonych w wysokiej klasy rdzeń mikrokontrolera Arm Cortex-M7 zamiast rdzenia Cortex-A.
Lattice Semiconductor również zapewnia rozwiązania AI oparte na rodzinach układów FPGA iCE40 i ECP5. Na przykład HM01B0, moduł czujnika obrazu o niskiej mocy oparty na iCE40, pozwala zaimplementować projekty referencyjne do rozpoznawania gestów rąk i wykrywania obecności ludzi. Aplikacja do wykrywania obecności ludzi zużywa zaledwie 1 mW w małym, kompaktowym urządzeniu. Projekt referencyjny zawiera wszystkie materiały potrzebne klientowi do odtworzenia kodu, w tym narzędzia do wprowadzania danych oraz przykładowe zestawy danych i strumienie bitów. Projekt może być skalowany w celu uruchomienia na platformie ECP5, aby uzyskać wyższą wydajność i większą funkcjonalność przy jednoczesnym zachowaniu niskiego zużycia energii.
Wybór taniego sprzętu
W przypadku wielu zastosowań właściwym wyborem będzie wnioskowanie AI w urządzeniu brzegowym, a nie w chmurze. Jak pokazują powyższe przykłady, sprzęt, który to umożliwia, istnieje już dziś i jest to ten sam sprzęt, z którym mają do czynienia programiści układów wbudowanych. Prawdą jest, że w przypadku wnioskowania z wykorzystaniem szybkiej sieci neuronowej, układy FPGA, takie jak PolarFire, oferują pewne korzyści w zakresie prędkości i mocy, ale niektóre rozwiązania nie potrzebują nawet sieci neuronowej. Tam gdzie skuteczny jest prostszy algorytm, sprzęt do jego obsługi może być tak samo prosty.
 Daniel Brzeziński z Rochester Electronics opowiada jak skutecznie zarządzać przestrzałością w branży półprzewodników
Daniel Brzeziński z Rochester Electronics opowiada jak skutecznie zarządzać przestrzałością w branży półprzewodników  AI podważa zasady, które rządziły branżą przez dekady. Moc obliczeniowa staje się nową walutą technologii
AI podważa zasady, które rządziły branżą przez dekady. Moc obliczeniowa staje się nową walutą technologii  Mieszacze aktywne – ćwiczenie z serii ADALM
Mieszacze aktywne – ćwiczenie z serii ADALM 






