





Jak w Linuksie działa Device Tree?
|
Szkolenie „Linux w systemach embedded” W dniach 25…29 listopada 2013 r. organizuję szkolenie dla wszystkich zainteresowanych rozwijaniem projektów opartych o Embedded Linux. Kurs daje solidną wiedzę i bazę do pogłębiania jej. Uczestnicy będą w stanie zaplanować, rozpocząć i rozwijać własny projekt. Praktyczne ćwiczenia są prowadzone na zestawie BeagleBone Black. Uczestnicy stopniowo implementują kolejne elementy systemu Linux i aplikacji. Po szkoleniu wszyscy uczestnicy otrzymują komputery na własność. Pozwala to samodzielnie rozwijać wiedzę a nawet budować prototypy własnych projektów. Marcin Bis |
Do niedawna jądro Linux było kompilowane razem z pełnym opisem peryferiów urządzenia do pojedynczego pliku zImage lub uImage. Bootloader ładował go następnie do pamięci operacyjnej. Ustawiał w rejestrze r1 „machine number” a w r2 wskaźnik do struktury ATAGS. Na końcu wykonywał skok do początkowego adresu jądra, po czym Linux przejmował kontrolę. ATAGS zawiera informacje takie, jak ilość pamięci i opcje jądra. Numer w r1 wskazuje na odpowiednią wkompilowaną strukturę, która opisuje konfigurację sprzętu.
Takie podejście powodowało konieczność umieszczania w kodzie jądra plików (.c) z opisem wszystkich wspieranych urządzeń. Dużo kodu było po prostu duplikowane. Co gorsza sposób konfiguracji znacznie różnił się pomiędzy różnymi rodzinami procesorów. Konfiguracja multipleksacji pinów zarówno w procesorach Freescale jak i Texas Instruments sprowadza się do wpisania odpowiednich wartości do odpowiedniego rejestru. Programiści nie lubią definiować do realizacji tych zadań różnych zestawów funkcji.
Stary sposób
Stary sposób na przykładzie (starego) AT91SAM9260. Plik: arch/arm/mach-at91/board-sam9260ek.c. Zaczniemy analizować go od końca:
/* Struktura opisująca urządzenie (zdefiniowana pomocniczymi makrami). AT91SAM9260EK - określa numer, który musi być przekazany w r1 (por.: arch/arm/tools/mach-types) */ MACHINE_START(AT91SAM9260EK, "Atmel AT91SAM9260-EK") /* Maintainer: Atmel */ /* ... kilka funkcji i struktur, które opisują/inicjują podstawowe elementy SoC-a ... */ /* Wskaźnik na funkcję, która zarejestruje urządzenia w systemie */ .init_machine = ek_board_init, MACHINE_END
Funkcja ek_board_init() ma za zadanie ustawić multipleksację pin-ów i zdefiniować struktury danych opisujące urządzenia.
static void __init ek_board_init(void)
{
/* Serial */
/* DBGU on ttyS0. (Rx & Tx only) */
at91_register_uart(0, 0, 0);
/* USART0 on ttyS1. (Rx, Tx, CTS, RTS, DTR, DSR, DCD, RI) */
at91_register_uart(AT91SAM9260_ID_US0, 1, ATMEL_UART_CTS | ATMEL_UART_RTS
| ATMEL_UART_DTR | ATMEL_UART_DSR | ATMEL_UART_DCD
| ATMEL_UART_RI);
/* ... */
}
at91_register_* i at91_add_* (używane dalej) są funkcjami z biblioteki dostarczającej opisu SoC-a. Układ plików różni się pomiędzy różnymi rodzinami procesorów. Jądro jest w stanie obsługiwać tylko ograniczoną ilość SoC-ów na raz. Dodanie kolejnego urządzenia wymaga kopiowania całego pliku (lub obudowania istniejącego masą dyrektyw preprocesora). Prowadziło to do bałaganu w kodzie.
Powyższe rozwiązanie jest jednak dość proste. Było używane w Linuksie od początku wsparcia dla architektury ARM. Użytkownicy i programiści zdążyli się do niego przyzwyczaić. Dodatkową zaletą jest fakt, że definicja sprzętu w postaci funkcji, jest bardzo elastyczna. Powyższy kod może odwołać się do jakichś rejestrów procesora, skopiować z nich potrzebne później dane, czy na przykład wysłać ciąg komend I2C aby włączyć i ustawić kontrolowany w ten sposób programowalny oscylator.
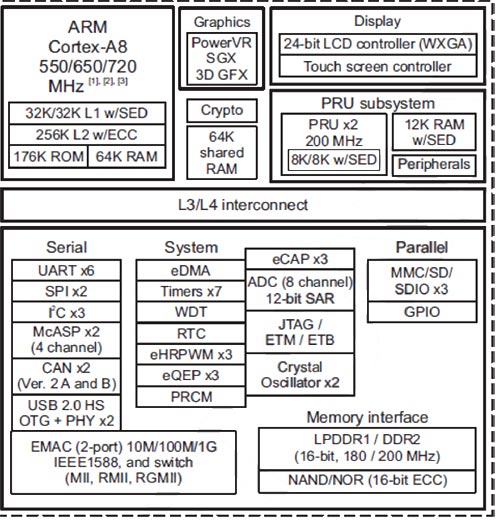
Rys 1. Schemat blokowy. SoC jest wyposażony w 6 modułów UART. Źródło: BeagleBone Black Reference Manual

Rys 2. Urządzenie zbudowane w oparciu o ten procesor – wykorzystujemy tylko jeden port szeregowy. Źródło: własne
Nowy sposób
W nowych wersjach jądrach do opisu sprzętu używane jest Device Tree. Istniejące pliki C opisujące sprzęt są stopniowo migrowane, nowe urządzenia dodawane są tylko w postaci Device Tree.
Linux nie zwraca już uwagi na zawartość rejestru r1. r2 natomiast musi zawierać wskaźnik do Device Tree. Aby ułatwić korzystanie ze starszych bootloaderów, jądro obsługuje opcję CONFIG_ARM_APPEND_DTB. Po jej włączeniu Linux spodziewa się Device Tree zaraz po końcu obrazu jądra.
cat arch/arm/boot/zImage arch/arm/boot/dts/moj.dtb > moj-zImage
Po co w ogóle jest Device Tree?
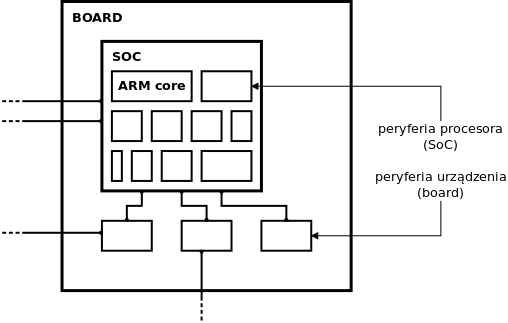
Rys 3. Procesory stosowane w systemach wbudowanych, mają wiele dodatkowych modułów. Zazwyczaj tylko część z nich jest wykorzystywana w konkretnym urządzeniu. System musi wiedzieć które
Producenci mikroprocesorów, bardzo często kupują gotowe bloki. Często używają też tych samych elementów w różnych układach scalonych. Na przykład:
- kontroler USB Freescale i.MX28 jest bardzo podobny do tego w i.MX6
- port szeregowy w RaspberryPi jest taki sam, jak wzorcowa implementacja UART firmy ARM (stosowana na przykład w emulatorze QEMU).
Skoro to takie same bloki, powinny być obsługiwane przez jeden sterownik. Ten jednak musi wiedzieć pod jakim adresem znajdzie rejestry. Albo jakie dodatkowe funkcje są włączone w danym bloku.
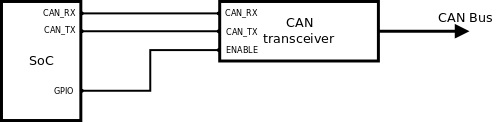
Rys 4. Peryferia mogą być podłączane na kilka sposobów. Na przykład transciever CAN wymaga zazwyczaj trzech linii. Dwie są dedykowane i służą do transmisji sygnałów. Trzecia umożliwia włączanie, wyłączanie układu. Można ją podłączyć do dowolnej linii GPIO. Żeby sterownik był uniwersalny, nie powinien zawierać zakodowanej definicji tej linii (na przykład adresu rejestru odpowiedzialnego za dany PIN). Przecież będzie ona różna w zależności od urządzenia. A co jeżeli nie jest to zwykłe GPIO, tylko ekspander I2C?
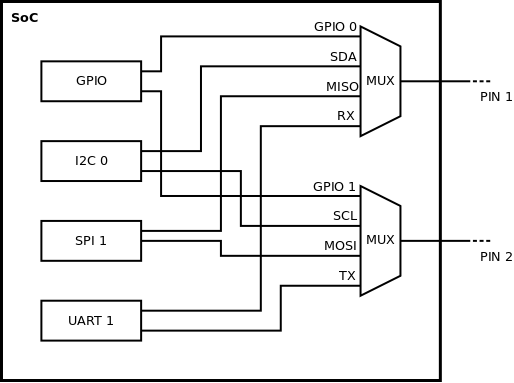
Rys 5. Układ nie ma wystarczającej ilości pin-ów do wyprowadzenia wszystkich funkcji. Konieczna jest ich multipleksacja. To kolejna informacja pasująca do Device Tree. Do tej pory zajmował się nią kod (makra, struktury, funkcje – w zależności od rodziny)
 |
Marcin Bis od 2007 roku zajmuje się zastosowaniami Linuksa w systemach embedded, przede wszystkim w rozwiązaniach przemysłowych działających w czasie rzeczywistym (real time applications). Konsekwentnie zdobywa doświadczenie praktyczne, uczestnicząc w projektach z dziedziny automatyki przemysłowej, domowej, multimediów, urządzeń sieciowych i wielu innych, zarówno w Polsce i za granicą. Swoją wiedzą i doświadczeniami dzieli się na konferencjach, prowadzi także szkolenia pod marką bis-linux.com. Zajmuje się zagadnieniami związanymi z projektowaniem urządzeń, portowaniem i uruchamianiem Linuksa, sterownikami urządzeń a także doborem komponentów OpenSource i wreszcie aplikacjami i skryptami składającymi się na gotowy system. Jest ponadto autorem pierwszej w języku polskim książki o zastosowaniach Linuksa w systemach embedded, która ukazała się nakładem Wydawnictwa BTC w roku 2011 („Linux w systemach embedded”). |
 Fotowoltaika perowskitowa: od wydajności laboratoryjnej do masowej komercjalizacji
Fotowoltaika perowskitowa: od wydajności laboratoryjnej do masowej komercjalizacji  Czy kamery termowizyjne pokazują nam całą prawdę?
Czy kamery termowizyjne pokazują nam całą prawdę?  Generowanie ujemnego napięcia odniesienia – eksperymenty z zestawem ADALM2000
Generowanie ujemnego napięcia odniesienia – eksperymenty z zestawem ADALM2000 

![O konkursie organizowanym przez firmę TRUMPF Huettinger i polskie uczelnie techniczne opowiada Alicja Peresada i prof. Jacek Rąbkowski oraz kilkoro nagrodzonych dyplomantów: mgr inż. Jakub Dobosz, inż. Maja Zielińska, dr inż. Jakub Kołodziej, dr inż Weronika Hryniewska-Guzik i dr inż. Grzegorz Bartyzel. Zapraszamy do obejrzenia filmu! [materiał redakcyjny]](https://mikrokontroler.pl/wp-content/uploads/2026/07/TRUMPF-czolowka.png "https://www.youtube.com/watch?v=XkeyLmtLfxo")



