





[FELIETON] Czy w najbliższej przyszłości językiem programowania systemów wbudowanych pozostanie C?
Jaki jest najlepszy język do napisania następnego projektu? Projektanci systemów wbudowanych nie mają wątpliwości – użyją C. Jeśli chcą zrobić wrażenie na kierownictwie, użyją C udającego C++. Być może niektóre krytyczne fragmenty kodu zostaną przepisane w asemblerze, jednak zgodnie z ostatnimi badaniami Barr Group, ponad 95% kodu systemu wbudowanych jest obecnie pisane w C lub C++.
Mimo to świat się zmienia. Nowi programiści, nowe architektury i nowe wyzwania uwalniają się od dominacji C w systemach wbudowanych. Zgodnie z jednym z najnowszych badań językiem najszybciej zdobywającym popularność jest Python, istnieje również wielu innych kandydatów w tym wyścigu. Pozostałe języki obecnie stanowią zaledwie ułamek istniejącego kodu. Jednak programista, który upiera się przy C/C++ może brzmieć podobnie do eksperta asemblera sprzed 20 lat: ta metoda generuje szybszy i bardziej niezawodny kod o mniejszej objętości, więc po co ją zmieniać?
Co mogłoby skłonić doświadczonego programistę do zmiany? Jakie języki mogłyby stać się prawdopodobnymi kandydatami systemów wbudowanych? A co ważniejsze, jak wyglądałby nowy, wielojęzyczny świat? Obrazek 1. przedstawia jedną z wizji. Sprawdźmy inne możliwości.

Rys. 1. Wprowadzenie nowych języków do systemów wbudowanych mogłoby zwiększyć produktywność albo – raczej – stworzyć wierzę Babel
Fala migracji
Jedną z przyczyn omawianego zjawiska jest przepływ programistów systemów wbudowanych z innych obszarów. Najbardziej oczywistym powodem jest wejście na rynek nowych absolwentów. Jeszcze niedawno student był wprowadzany do programowania poprzez kurs języka C, a większość projektów robił właśnie w C lub w C++. Nie jest to już prawdą. „Obecnie większość kursów informatyki wykorzystuje Python jako język wprowadzający” – obserwuje kierownik działu inżynierii oprogramowania Intela David Stewart. Możliwe jest ukończenie kursu informatyki z dobrą znajomością Pythona, Ruby i innych języków skryptowych, ale bez stosowania C na większą skalę.
Istotne są też inne źródła. Wykorzystanie platformy Android dla sieciowych aplikacji wbudowanych otwiera drogę do natywnego języka Androida, Java. Na drugim końcu skali pod względem złożoności znajdują się hobbyści tworzący roboty, drony i podobne projekty oparte na Arduino czy Raspberry Pi. Mają oni doświadczenie w prostych, kompaktowych kreatorach lub zwięzłych językach, takich jak B#.
Dyskusje o internecie przedmiotów (IoT) także mają wpływ na rynek, przyciągając twórców aplikacji sieciowych. Jeśli zewnętrznym intefejs systemu wbudowanego jest zgodny z RESTful Web, odpowiednim językiem programowania powinien być JavaScript lub jego serwerowy kuzyn Node.js. Nawet najwięksi entuzjaści C muszą przyznać, że Node.js, skalowalna platforma często używana przez takie przedsiębiorstwa, jak PayPal czy Walmart, ma najszybciej rosnący ekosystem spośród wszystkich języków programowania (dane ze strony modulecounts.com).
Przyczyna popularności Node.js jest częściowo kulturowa, ale też wynika z rozwiązań architektonicznych. Filozofia IoT rozdziela zadania systemu wbudowanego między klienta – związanego ze światem zewnętrznym i często wykorzystującym minimalne zasoby sprzętowe, oraz serwer dostępny za pośrednictwem internetu. Naturalne rozwiązanie to klient stanowiący aplikację sieciową używającą biblioteki związanej ze sprzętem oraz typowa aplikacja serwerowa. Dla programisty sieciowego system IoT jest oczywistym obszarem zastosowań języków JavaScript oraz Node.js.
Rosnąca złożoność algorytmów w systemach wbudowanych to kolejny czynnik, który wymusza zmiany. Proste pętle kontroli w filtrach Kalmana, sieciach neuronowych i systemach kontroli opartych na modelach przy zachowaniu dużej wydajności – to znów Python. Również języki takie, jak OpenCL (Open Computing Language) i środowiska oparte na modelach, jak Matlab, zdobywają dużą popularność.
Silna motywacja
Dlaczego nowi programiści nie chcą się uczyć C? „Prawdziwą motywacją jest produktywność programisty”, mówi Stewart. Krytycy C od dawna twierdzą, że pisanie w C jest powolne i łatwo o błędy. Programy mogą wykazywać nieoczekiwaną zależność od sprzętu i z reguły są niemożliwe do oczytania przez kogokolwiek poza oryginalnym autorem. Żadna z tych cech nie zwiększa produktywności i wszystkie one uniemożliwiają osiągnięcie największego zysku produktywności, którym jest powtórne wykorzystanie projektu.
W odróżnieniu od C, wiele współczesnych języków programowania próbuje zarówno być przystępnych dla użytkowników, jak i ułatwiać powtórne wykorzystanie kodu. Choć niemal wszystkie języki używane obecnie próbują uprościć gęstą składnię C, ostatnio duży nacisk jest kładziony na czytelność zamiast minimalizacji liczby znaków. Komentarze na końcu linii w C stanowią często dość luźne przemyślenia, dzięki którym autor może zrozumieć własny kod. W nowoczesnych językach komentarze są nie tylko zalecane, ale też ich struktura podlega określonym standardom. Ich przestrzeganie pozwala na przykład tworzyć programy, które generują instrukcję użytkownika na podstawie zorganizowanych komentarzy w module Pythona.
Współczesne języki zapewniają także struktury danych wysokiego poziomu. O ile w C++ można z pewnością utworzyć dowolny obiekt i wykorzystać go ponownie z pomocą sprytnych operacji na wskaźnikach, to Python na przykład dostarcza wbudowane typy List i Dictionary (słownika). Inne języki, takie jak Ruby, są całkowicie obiektowe, dzięki czemu struktury i ponowne wykorzystanie kodu stają się naturalnymi narzędziami programisty.
Dwa ważne atrybuty sprawiają, że powtórne wykorzystanie kodu we współczesnych językach jest proste. Po pierwsze, co może wydać się kontrowersyjne, jest to dynamiczne rozpoznawanie typu. W praktyce wszystkie języki używane po stronie serwera są interpretowane, a nie kompilowane. Gdy używana jest zmienna, interpreter dedukuje typ danych występujących w wyrażeniu. Następnie wybiera odpowiednią operację, aby wyznaczyć wartość wyrażenia dla danych tego typu. Zdejmuje to z programisty konieczność sprawdzenia, czy np. dane funkcja oczekuje liczby całkowitej, czy rzeczywistej. Jednak programiści systemów wbudowanych i eksperci od niezawodności kodu zauważają, że dynamiczne określenie typu jest ze swej natury mało wydajne i może prowadzić do zupełnie nieoczekiwanych rezultatów – zgodnych z intencją lub nie.
Drugim atrybutem jest modularność. Czasami mówi się, że Python nie jest wcale językiem programowania, tylko skryptów: grupowaniem wywołań do funkcji napisanych niegdyś w C przez kogoś innego.
Te atrybuty – czytelność, dokumentacja w kodzie, dynamiczne ustalanie typu i wielokrotne użycie funkcji – spowodowały błyskawiczny rozwój ekosystemu w świecie opern-source. Programiści instynktownie poszukują rozbudowanych bibliotek open-source, takich jak npm (dla Node.js), PyPI (dla Pythona) czy Rubygems.org (dla Ruby) w poszukiwaniu funkcji, których mogliby użyć. Jeśli muszą zmodyfikować wartość lub stworzyć nową, wyniki ich pracy zostaną dodane do biblioteki. W rezultacie biblioteki rozwijają się: npm obecnie zawiera około ćwierć miliona modułów. Te ogromne ekosystemy następnie przekładają się na wzrost produktywności programistów.
Problemy
Nowe języki, przy tak wielu zaletach, muszą też mieć wady. Jest wiele powodów, dla którego zmiany jak dotąd nie przyjęły się na rynku.
Najbardziej oczywisty problem polega na tym, że omawiane jeżyki są interpretowane, a nie kompilowane. Oznacza to duży rozmiar kodu uruchomieniowego, który obejmuje sam interpreter, pamięć roboczą, narzut na dynamiczne rozpoznawanie typu, biblioteki uruchomieniowe i inne. Wszystkie one muszą zmieścić się w pamięci systemu wbudowanego. W teorii ich rozmiar może być całkiem kompaktowy – niektóre maszyny wirtualne Javy zajmują dziesiątki kilobajtów. Ale Node.js, Python i podobne języki dla serwerów wymagają więcej miejsca. Maszyna wirtualna Pythona zachowująca praktyczną kompatybilność prawdopodobnie zajmie kilka megabajtów i to bez właściwego kodu użytkownika.
Kolejnym problemem jest wydajność. Interpretery odczytują linię kodu – źródłowego lub pośredniego – parsują, sprawdzają pod kątem błędów i wywołują procedury, które wykonują żądane operacje. Może to doprowadzić do dużego obciążenia dla linii kodu, którą kompilator C przekształciłby na zaledwie kilka instrukcji maszynowych. Prowadzi to nie tylko do wydłużenia czasu wykonania, ale też wzrostu zużywanej energii.
Wydajność w czasie pracy nie jest przeszkodą nie do ominięcia. Jednym ze sposobów jest wykorzystanie kompilatora just-in-time (JiT). Pracuje on równolegle do interpretera i generuje skompilowane instrukcje maszynowe dla kodu wewnątrz pętli, dzięki czemu kolejne obiegi są szybsze. „Techniki JiT są bardzo interesujące.” – mówi Stewart. „Kompilator PyPy JiT przyspiesza wykonywanie kodu Pythona około dwukrotnie.”
Ponadto wiele funkcji wywoływanych przez programy zostało oryginalnie napisanych w C. Są one wywoływane przez pośrednie funkcje interfejsu. Często wykorzystywane funkcje mogą pracować z szybkością kodu C, bo w istocie są skompilowanym kodem C.
Badane są również inne pomysły. Jeśli na przykład funkcje są nieblokujące lub wykorzystują mechanizm sygnałów, program zawierający wiele wywołań funkcji może pracować w wielu wątkach jednocześnie, nawet przed zastosowaniem technik w rodzaju rozwijania pętli do stworzenia większej liczby wątków. Istnieje zatem potencjał wykorzystania wielu wielowątkowych rdzeni w jednym module. Technika ta została dobrze zbadana w klastrach obliczeniowych. Co więcej, Ruby obsługuje wielowątkowość na poziomie języka, więc może wygenerować wielowątkowy kod nawet, jeśli sam system operacyjny nie obsługuje wątków. Niektóre zespoły próbują zaimplementować biblioteki lub moduły w platformach sprzętowych, takich jak karty graficzne, Xeon Phi czy FPGA. W praktyce również sam interpreter może wykonywać operacje możliwe do akceleracji.
Inną trudnością w przypadku języków działających po stronie serwera jest brak środków pozwalających komunikować się ze światem zewnętrznym. Nie ma obsługi rygorów czasu rzeczywistego czy wejścia/wyjścia poza siecią i urządzeniem magazynującym serwera. Ten problem znalazł kilka rozwiązań.
Najbardziej oczywiste jest rozwiązanie w systemie Android, które zamyka kod Javy w niemal niezależnej od sprzętu abstrakcyjnej powłoce. Jest to maszyna wirtualna z obsługą grafiki, ekranów dotykowych, audio i wideo, wielu sieci i fizycznych czujników. Lżejszą platformę stanowi Java Embedded skupiająca się głównie na komunikacji z fizycznymi układami. Może ona pracować nawet na mikrokontrolerze.
Języki takie jak Python wymagają odmiennego podejścia. Ponieważ interpreter CPython pracuje pod Linuksem, teoretycznie może działać na dowolnym systemie wbudowanym, którego wydajność i rozmiar pamięci pozwalają uruchomić Linuksa. Były podejmowane próby dalszej adaptacji CPythona poprzez skrócenie narzutu na ładowanie, zapewnienie funkcji dostępu do fizycznych wejść/wyjść i wykorzystania sprzętowej akceleracji, a także pracy w reżimie czasu rzeczywistego. Jednym z przykładów jest środowisko Micro Python pracujące bezpośrednio na mikrokontrolerach STM32. Choć może wydawać się to nieprawdopodobne, tego rodzaju próby są również wykonywane na języku Node.js.
Kwestie bezpieczeństwa sprawiają kolejne problemy. Wiele standardów niezawodności i bezpieczeństwa odradza lub całkowicie zabrania wykorzystania otwartego kodu, który nie został wyczerpująco przetestowany lub jego poprawność nie została formalnie dowiedziona. Te ograniczenia mogą sprawdzić, że powtórne wykorzystanie modułu nie będzie możliwe lub stanie się tak skomplikowane, że nie zwiększy produktywności. Jednocześnie te same wymagania będą stawiane otwartym środowiskom, takim jak maszyny wirtualne. Otwarta platforma typu CPython oznacza ogromne kłopoty dla społeczności dbającej o bezpieczeństwo.
Ostatecznie, uwzględniając wiele czynników wprowadzających nowe języki do świata systemów wbudowanych, można sobie wyobrazić systemy korzystające z modułów napisanych w różnych językach. Każdy z nich miałby dostęp do kluczowych bibliotek lub został wybrany ze względu na wygodę projektanta. Można oczywiście utrzymywać kilka maszyn wirtualnych na różnych procesorach, ale też zintegrować je pod kontrolą jednego rdzenia, a komunikację między procesami zapewniać poprzez wywołania funkcji. Jednak powstały w ten sposób system byłby ogromny.
Inna możliwością jest zestaw interpreterów konkretnych języków tworzących taki sam kod pośredni dla interpretera JiT (rysunek 2). Z pewnością jest tu kilka problemów do rozwiązania – takich, jak różne modele komunikacji między procesami, modele pamięci i narzędzia do debugowania – ale narzut powinien być możliwy do zaakceptowania.
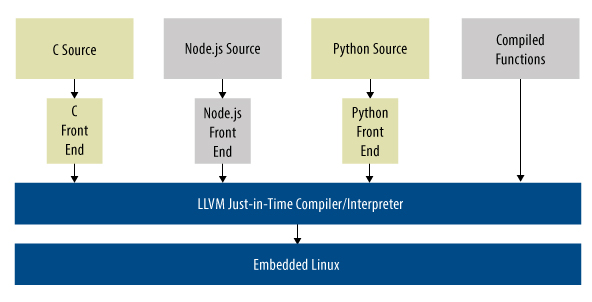
Rys. 2. Jednorodne środowisko uruchomieniowe mogłoby obsługiwać wiele języków interpretowanych w systemie wbudowanym
Jeśli te rozwiązania pojawią się, czym powinien zająć się doświadczony programista systemów wbudowanych? Warto przyjrzeć się jeżykom dla aplikacji sieciowych, serwerów nawet hobbystów. Można spróbować napisać moduł do następnego projektu zarówno w C++, jak i w języku interpretowanym. Nauka może zabrać trochę czasu, ale dodatkowy wysiłek zapewnia możliwość równoległego tworzenia projektu – najlepszy sposób na zapewnienie poprawności.
Jednak zdecydowana większość kodu w dzisiejszych systemach zbudowanych jest napisana w C. Jest wielu doświadczonych programistów C, ponadto ten język daje lepszy kod wynikowy. Jednak zupełnie tak samo wyglądała sytuacja asemblera 20 lat temu, a obecnie pokolenie programistów asemblera jest na wymarciu.
Czy historia się powtórzy?
Ron Wilson, Altera
 Grzegorz Kamiński: Dlaczego powstały tranzystory FinFET i GAAFET?
Grzegorz Kamiński: Dlaczego powstały tranzystory FinFET i GAAFET?  Google stawia na fuzję jądrową. AI potrzebuje coraz więcej energii
Google stawia na fuzję jądrową. AI potrzebuje coraz więcej energii  Fotowoltaika perowskitowa: od wydajności laboratoryjnej do masowej komercjalizacji
Fotowoltaika perowskitowa: od wydajności laboratoryjnej do masowej komercjalizacji 

![O konkursie organizowanym przez firmę TRUMPF Huettinger i polskie uczelnie techniczne opowiada Alicja Peresada i prof. Jacek Rąbkowski oraz kilkoro nagrodzonych dyplomantów: mgr inż. Jakub Dobosz, inż. Maja Zielińska, dr inż. Jakub Kołodziej, dr inż Weronika Hryniewska-Guzik i dr inż. Grzegorz Bartyzel. Zapraszamy do obejrzenia filmu! [materiał redakcyjny]](https://mikrokontroler.pl/wp-content/uploads/2026/07/TRUMPF-czolowka.png "https://www.youtube.com/watch?v=XkeyLmtLfxo")



