





Akcelerator grafiki 2D na FPGA i STM32F429
Wykorzystanie zasobów FPGA
Każdy projekt FPGA musi zmieścić się w ograniczeniach na powierzchnię i szybkość pracy układu. Powierzchnia to maksymalna liczba bramek dostępnych w FPGA, w których muszą zmieścić się wszystkie układy logiczne. W przypadku problemów możliwe są dalsze sztuczki i optymalizacja, ale jeśli nie okażą się one skuteczne, może zajść potrzeba kupna większego układu – a to bywa kosztowne. Poniżej widać uzyskane przeze mnie wykorzystanie układu:
Device utilization summary: --------------------------- Selected Device : 3s50vq100-5 Number o Slices: 795 out of 768 103% (*) Number of Slice Flip Flops: 875 out of 1536 56% Number of 4 input LUTs: 1406 out of 1536 91% Number used as logic: 1326 Number used as RAMs: 80 Number of IOs: 61 Number of bonded IOBs: 61 out of 63 96% Number of BRAMs: 4 out of 4 100% Number of GCLKs: 3 out of 8 37% Number of DCMs: 1 out of 2 50%
Lubię dostawać to, za co płacę, więc wykorzystanie 103% komórek logicznych przyjąłem za dobrą monetę. Ale czy to nie oznacza przekroczenia dostępnych zasobów? Tak, ale to tylko wstępne oszacowanie narzędzia syntezy xst. Ważne są wyniki narzędzia map, które faktycznie umieszcza skompilowany projekt w fizycznym układzie i próbuje go optymalizować. Użyłem map z flagą oznaczającą maksymalną optymalizację zasobów, co dało następujące rezultaty:
Design Summary -------------- Design Summary: Number of errors: 0 Number of warnings: 14 Logic Utilization: Number of Slice Flip Flops: 913 out of 1,536 59% Number of 4 input LUTs: 1,375 out of 1,536 89% Logic Distribution: Number of occupied Slices: 760 out of 768 98% Number of Slices containing only related logic: 760 out of 760 100% Number of Slices containing unrelated logic: 0 out of 760 0% *See NOTES below for an explanation of the effects of unrelated logic. Total Number of 4 input LUTs: 1,449 out of 1,536 94% Number used as logic: 1,286 Number used as a route-thru: 74 Number used for Dual Port RAMs: 80 (Two LUTs used per Dual Port RAM) Number used as Shift registers: 9 The Slice Logic Distribution report is not meaningful if the design is over-mapped for a non-slice resource or if Placement fails. Number of bonded IOBs: 61 out of 63 96% IOB Flip Flops: 2 Number of RAMB16s: 4 out of 4 100% Number of BUFGMUXs: 3 out of 8 37% Number of DCMs: 1 out of 2 50% Average Fanout of Non-Clock Nets: 3.23
Teraz sytuacja wygląda znacznie lepiej i daje prawdziwy wgląd w rzeczywisty stopień wykorzystania zasobów układu.
Spełnienie wymagań czasowych oznacza, że opóźnienie najwolniejszej ścieżki sygnału musi być krótsze, niż okres między dwoma zboczami zegara. Opóźnienie sygnału wynika z czasów, których potrzebują układy kombinacyjne, a także opóźnień ścieżek wynikających ze skończonej szybkości przepływu prądu w układzie. Próba spełniania wymagań czasowych może być błądzeniem po omacku – czasem z pozoru nieistotne modyfikacje zmieniają końcowy wynik o całe megaherce. Jeśli jednak wymagania czasowe zostaną spełnione, dalsza praca nie ma sensu – nie spowoduje to już żadnej zmiany w działaniu projektu.
Narzędzia Xilinx raportują najgorszy przypadek opóźnienia w zakładce „post-place and route static timing results”. Wymagana częstotliwość pracy mojego projektu to 100 MHz, a wyniki są następujące:
Design statistics:
Minimum period: 9.516ns{1} (Maximum frequency: 105.086MHz)
Jest to wystarczający margines. Jak wspomniałem wyżej, nie ma sensu poprawiać tego wyniku – projekt będzie pracował dokładnie z taką samą szybkością.
Aplikacje testowe
Pierwsza aplikacja testowa ma na celu sprawdzić, czy poprawnie działa obsługa wyświetlacza LCD w trybie transferu. Aby to sprawdzić, wykorzystam bibliotekę graficzną stm32plus, by wyświetlić pewne testowe kolory. Podsystem grafiki stm32plus jest oparty o hierarchiczną strukturę, która rozdziela odpowiedzialność za algorytmy rysowania wysokiego poziomu od obsługi sterownika LCD. Ten z kolei jest oddzielony od metod zapewniających dostęp do sterownika.
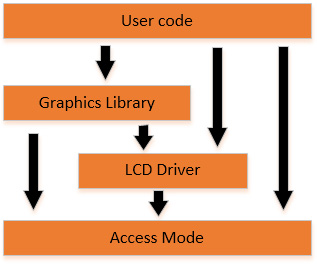
Do tej pory używałem trybów dostępu, które polegają albo na wykorzystanie układu peryferyjnego STM32 FSMC, albo użyciu pinów GPIO do sterowania wyświetlaczem LCD. Aby moja własne płytka działała z całą zawartością biblioteki stm32plus, musiałem jedynie napisać klasę trybu dostępu, która realizuje zadanie wysyłania danych na 10-bitową szynę. Nazwałem ją AseAccessMode, gdzie „Ase” oznacza „Andy’s Sprite Engine”.
Przewidywalne zależności czasowe są bardzo istotne, aby zapewnić poprawną pracę trybu transferu. Ważny jest czas włączenia, a szczególnie czas trwania sygnału WR. Układ FPGA wymaga 4 cykli zegara lub 40 ns pomiędzy narastającymi zboczami sygnału WR, aby być gotowym na odbiór kolejnego narastającego zbocza. Następujący kod assemblera pozwala klasie AseAccessMode na przesłanie polecenia do FPGA:
inline void AseAccessMode::writeFpgaCommand(uint16_t value) const {
// 20ns low, 20ns high = 25MHz max toggle rate
__asm volatile(
" str %[value_low], [%[data]] \n\t" // port <= value (WR = 0)
" dsb \n\t" // synchronise data
" str %[value_low], [%[data]] \n\t" // port <= value (WR = 0)
" dsb \n\t" // synchronise data
" str %[value_low], [%[data]] \n\t" // port <= value (WR = 0)
" dsb \n\t" // synchronise data
" str %[value_high], [%[data]] \n\t" // port <= value (WR = 1)
" dsb \n\t" // synchronise data
" str %[value_high], [%[data]] \n\t" // port <= value (WR = 1)
" dsb \n\t" // synchronise data
" str %[value_high], [%[data]] \n\t" // port <= value (WR = 1)
" dsb \n\t" // synchronise data
:: [value_low] "l" (value), // input value (WR = 0)
[value_high] "l" (value | 0x400), // input value (WR = 1)
[data] "l" (_busOutputRegister) // the bus
);
}
Instrukcja dsb (Data Synhronization Barrier) jest bardzo ważna, aby zagwarantować przewidywalny czas wykonania. Bez niej zaawansowany rdzeń mikrokontrolera F4 dokonałby optymalizacji potoku instrukcji i doprowadził do rezultatu, który nie spełnia ostrych wymagań czasu wykonania instrukcji podanych w podręczniku użytkownika ARM. Zaprojektowałem tryb transferu tak, aby wymagał jedynie dwóch taktów do przesłania 16-bitowych danych lub treści polecenia do wyświetlacza LCD, albo też mógł w tym czasie przejść w tryb obsługi bitmap.
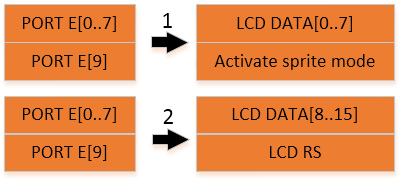
Pierwszy transfer polega na przesłaniu pierwszych 8 bitów 16-bitowej wartości dla wyświetlacza LCD. Jeśli ustawiony jest najstarszy bit portu E, system przejdzie natychmiast w tryb obsługi bitmap i drugi transfer nie nastąpi.
Drugi transfer polega na przesłaniu starszych 8 bitów 16-bitowej wartości. Jeśli ustawiony jest najstarszy bit, wartość ta oznacza wybór linii (register select, RS) wyświetlacza LCD.

Kod źródłowy testu transferu jest dostępny na Githubie. Byłem bardzo zadowolony, gdy ten test się powiódł – po raz pierwszy zobaczyłem działający ekran LCD, który wyświetlał dane pod kontrolą FPGA, nawet jeśli całością zarządzał mikrokontroler w trybie transferu.
Manic Knights
Na samym początku artykułu obiecałem demo gry i zamierzam dotrzymać tej obietnicy. Stworzę demo, wykorzystując wysokiej jakości grafiki, które przedstawiają przykładową platformówkę, jaką można zrealizować na tym systemie. Gra będzie wykorzystywać animowane bitmapy, które poruszają się po nieliniowych trajektoriach wykorzystujących funkcje wygładzania. Funkcje te obciążają jednostkę zmiennoprzecinkową (FPU) układu F4, aby płynnie zmieniać szybkość animacji. Gra pozwoli również na przewijanie okna widoku we wszystkich 4 kierunkach, co pozwala graczowi na poruszanie się w świecie znacznie większym od ekranu.
Kafelkowa mapa
Świat gry stanowi matryca kafelków o wymiarach 20 x 30. Każdy kafelek jest kwadratem o boku 64 pikseli. Wykorzystałem darmowy edytor Tiled, aby stworzyć mapę z użyciem zestawu grafik kupionych w serwisie cartoonsmart.com. Dostępne są też darmowe grafiki, ale ich jakość nie jest powalająca. Uznałem, że lepiej będzie wydać kilka dolarów na grafiki komercyjnej jakości.
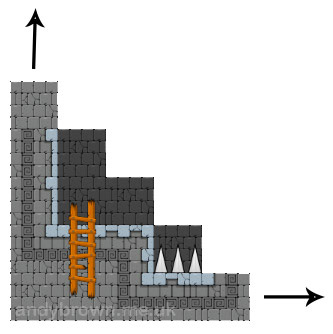
Edytor map Tiled pozwala szybko zbudować świat gry i zapisać go w pliku XML, który następnie można sparsować i przedstawić w dowolnym wymaganym formacie. Głównym problemem jest to, że edytor działa w trybie poziomym (landscape), natomiast silnik gry pracuje w trybie pionowym (portrait). Musi tak być, aby zachować synchronizację z odświeżaniem wyświetlacza, które zawsze przebiega pionowo, niezależnie od logicznej orientacji wyświetlacza.
Aby rozwiązać ten problem, napisałem mały program C#, który eksportuje kafelki do formatu PNG i obraca je przy tym o 90° w kierunku przeciwnym ruchu do wskazówek zegara. To, wraz z kodem Perl łączącym całość, pozwala edytorowi Tiled na tworzenie plików wyjściowych, które można łatwo załadować do pamięci Flash.

Powyższy obrazek przedstawia kompletny świat gry, obrócony z powrotem do formatu poziomego na potrzeby artykułu. Ten świat będzie stanowił tło gry. W implementacji gry rezerwuję na początku tablicy bitmap zapas slotów, które są przeznaczone na tło. Gdy gracz porusza się w świecie gry, te zarezerwowane sloty są aktualizowane, dzięki czemu cały czas znajdują się na odpowiedniej siatce tła w danej pozycji. Ponieważ bitmapy są umieszczone na początku tablicy, zawsze będą wyświetlane za innymi bitmapami, które będą rysowane w dalszej kolejności. Konkretnie będą to…
 Jak model Industry 5.0 wspiera zrównoważony rozwój w polskim przemyśle
Jak model Industry 5.0 wspiera zrównoważony rozwój w polskim przemyśle  Daniel Brzeziński z Rochester Electronics opowiada jak skutecznie zarządzać przestrzałością w branży półprzewodników
Daniel Brzeziński z Rochester Electronics opowiada jak skutecznie zarządzać przestrzałością w branży półprzewodników  AI podważa zasady, które rządziły branżą przez dekady. Moc obliczeniowa staje się nową walutą technologii
AI podważa zasady, które rządziły branżą przez dekady. Moc obliczeniowa staje się nową walutą technologii 






