





Automatyczne rozpoznawanie mowy w urządzeniach typu smart i towarzyszące temu wyzwania
Artykuł ten prezentuje spojrzenie na rozpoznawanie mowy w urządzeniach typu smart. Opisywane są w nim różne technologie, które powodują, że to niezwykłe narzędzie tak dobrze sprawdza się
w codziennym życiu konsumentów.

Technologia rozpoznawania mowy pojawia się w różnych aplikacjach i produktach końcowych. Badania nad wykorzystaniem mowy do wyszukiwania sugerują, że do 2020 roku połowa wszystkich wyszukiwań będzie wykonywana za pomocą głosu (źródło: ComScore). Używanie głosu jest szybkie i nie wymaga pisania na klawiaturze, co jest o wiele wygodniejsze do użytkowania na smartfonie.
Innym produktem, dzięki któremu automatyczne rozpoznawanie mowy zyskuje na popularności, jest inteligentny głośnik. Inteligentne głośniki Google Home™ oraz Amazon’ Echo i Dot wkradają się do domów szybciej niż większość była w stanie przewidzieć, jak widać na rysunku 1. Apple także ma udziały w rynku wraz ze swoim głośnikiem HomePod™.
 Rysunek 1. Google Home, Amazon Echo i inne inteligentne głośniki
Rysunek 1. Google Home, Amazon Echo i inne inteligentne głośniki
Dla klienta nie ma różnicy między mówieniem do inteligentnego głośnika, a do smartfona. Klienci oczekują wręcz takich samych możliwości rozpoznawania mowy, jakie ma ich smartfon, mimo że implementacja inteligentnego głośnika jest o wiele trudniejsza z akustycznego punktu widzenia.
Działanie inteligentnego głośnika
Inteligentny głośnik posiada unikatowy zestaw wymagań dot. działania. Po pierwsze, inteligentny głośnik zawsze nasłuchuje: czeka na odpowiedni sygnał albo odpowiednie słowo, które go wybudzą, zanim połączy się z chmurą, w której zachodzi przetwarzanie dźwięku. Słowo ‘Alexa’ pobudza do działania głośnik Amazona. Polecenia ‘OK Google’ dla Google Home czy ‘Hey Siri’ dla produktu Apple’a nie brzmią już tak naturalnie. Prowadzą do dziwnych konstrukcji albo do wydawania krótkich poleceń jak ‘OK Google, wyłącz światła’ albo ‘OK Google, podkręć głośność’.W przypadku Amazon Echo, wykrycie słowa wybudzającego odbywa się lokalnie. To ważne: jeśli nie działoby się to za pośrednictwem samego głośnika, urządzenie musiałoby ciągle wysyłać pakiety głosowe do chmury w celu przetworzenia.
Kiedy słowo wybudzające zostanie wykryte, użytkownik wypowiada komendę, np. ‘Włącz światło w kuchni’. Podłączone urządzenie wysyła to polecenie do chmury obliczeniowej Amazon Web Services (AWS),. Po rozszyfrowaniu wiadomości, ‘instruuje’ światło w kuchni, by je włączyć.
Architektura ta działa, ponieważ programiści wbudowali umiejętności przeznaczone dla serwisów głosowych Amazon Alexa w urządzenia działające na AWS, jak widać na rysunku 2.
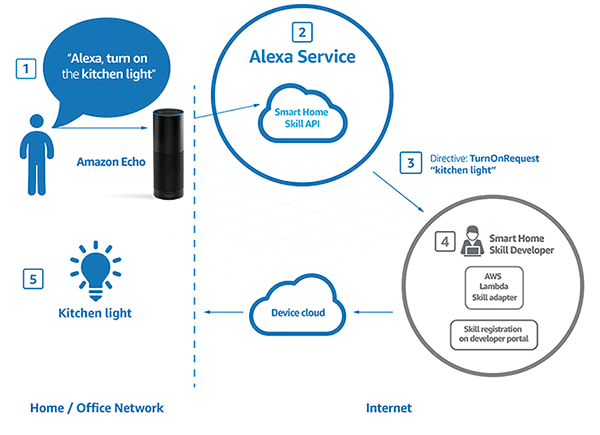
Rysunek 2. Architektura poleceń dla serwisu głosowego Amazon Alexa. (źródło: developer.amazon.com)
Implementacja rozpoznawania mowy w urządzeniach, które znajdują się 10 metrów od użytkownika, może napotykać pewne problemy. Odległość to nie jedyne wyzwanie dla inteligentnego głośnika: nakładanie się odbitych od ścian odgłosów pochodzących z grającego głośnika czy inne dźwięki powodują, że inteligentny głośnik może mieć problemy z odróżnieniem głosu użytkownika i rozpoznaniem słów. Kluczem do rozwiązania tego problemu jest wdrożenie technologii ASR Assist, tak jak to pokazano na rysunku 3.
Kształtowanie wiązki: nie jest niczym niezwykłym znalezienie kilku źródeł dźwięku w pokoju. Technologia lokalizacji źródła dźwięku, oddzielająca dźwięk będący obiektem zainteresowania, nazywa się kształtowaniem wiązki i minimalizuje amplitudę niepożądanych sygnałów i szumów. Aby skutecznie przeprowadzić formowanie wiązki, tablica mikrofonów implementuje filtrowanie przestrzenne. Mikrofony zbierają rozchodzące się fale, by utworzyć z nich próbki przestrzenne. Filtrowanie przestrzenne wymaga informacji o charakterystyce mikrofonów i konfiguracji matrycy mikrofonów.
Wtrącenie: inteligentny głośnik może wskazać nie tylko czas czy powiedzieć pogodę, ale użytkownik często będzie także prosił urządzenie o odtworzenie muzyki. Wtrącenie pozwala na wykrywanie odpowiednich słów wyzwalających podczas grania muzyki.
Usuwanie pogłosu: funkcjonalność ta usuwa echo w pokoju w celu poprawy przejrzystości głosu.
Automatyczna kontrola wzmocnienia: użytkownik może znajdować się czasem tuż przy głośniku, innym razem 5 metrów dalej. Automatyczna kontrola wzmocnienia stosuje odpowiednie wzmocnienie sygnału dla odległości, z której pochodzi głos.
Redukcja hałasu: funkcjonalność ta łagodzi wpływ szumów pochodzących z otoczenia, np. wiatraków.

Rysunek 3. Technologie ASR Assist. (źródło: Microsemi)
DSP czy MCU?
Technologie ASR Assist pozwalają inteligentnemu głośnikowi na przetwarzanie mowy na odległość w hałaśliwych warunkach. Technologia znajdująca się w sprzęcie, stanowiąca podstawę ASR Assist, to cyfrowe przetwarzanie sygnału, które zostało wdrożone w wyspecjalizowanych mikroprocesorach mających specjalną architekturę.
Możliwe jest cyfrowe przetworzenie sygnałów w MCU ogólnego przeznaczenia, który używa algorytmów cyfrowego przetwarzania sygnałów, jednakże bardziej efektywnie jest użyć płytki zawierającej procesor DSP.
Dla zastosowań ASR najlepsze środowisko zapewniają wyspecjalizowane produkty audio DSP, w których to można implementować funkcję ASR Assist. Podstawowym przykładem takiego urządzenia jest ZL38063 od Microsemi.
ZL38063 jest częścią rodziny procesorów audio Timberwolf firmy Microsemi. Poprawia wydajność ASR na długich dystansach, jednocześnie zapewniając możliwości wtrąceń, i jest zoptymalizowany tak, by wykrywać komendy głosowe. Technologia AcuEdge™ firmy Microsemi, która pojawia się w ZL38063, jest przeznaczona do użytku w telewizorach, dekoderach i inteligentnych głośnikach, ale sprawdza się również w innych zastosowaniach dla inteligentnego domu. Urządzenie jest w stanie zarówno sterować głosem, jak i dwukierunkowym sygnałem full duplex zawierającym ulepszony głos, z wyeliminowanym efektem echa i redukcją szumów tak, by poprawić zrozumiałość i jakość głosu w trudnych warunkach środowiskowych.

Rysunek 4. Uproszczony diagram blokowy procesora audio ZL38063. (źródło: Microsemi)
Innym nośnikiem, dzięki któremu można wdrażać zaawansowane technologie rozpoznawania mowy jest cyfrowy kontroler sygnału (DSC). To stwarza wiele korzyści dla projektantów systemów OEM. Zastąpienie projektu opartego na kombinacji mikrokontrolera i procesora DSP pojedynczym kontrolerem sygnału może obniżyć koszty materiałów. Ponadto, może zapewnić zmniejszenie złożoności na poziomie systemu poprzez wyeliminowanie potrzeby współdzielenia pamięci, komunikacji pomiędzy MCU i DSP, złożonej architektury szyn wieloprocesorowych oraz niestandardowego interfejsu cyfrowego pomiędzy MCU i DSP.
DSC ma także zaletę redukcji kosztów oprogramowania, ponieważ cały projekt może być opracowany za pomocą pojedynczego kompilatora, debuggera i zintegrowanego środowiska programistycznego. Zamiast programować ręcznie w assemblerze pod konkretny DSP, oprogramowanie może również zostać napisane w języku wysokiego poziomu takim jak C albo C++. Produkty Microchip z rodziny dsPIC33E/F DSC mogą być używane w zastosowaniach ASR, ponieważ oferują one takie funkcje jak kodowanie i dekodowanie mowy, tłumienie szumu, eliminację akustycznego/ liniowego echa, stabilizator oraz automatyczna kontrola wzmocnienia.
Podejście Amazona do implementacji możliwości ASR w inteligentnym głośniku Echo polega na integracji audio DSP z urządzeniem. Audio DSP wykonuje większość operacji wymaganych przez funkcje ASR Assist. Czysty sygnał jest następnie wysyłany do procesora aplikacji poprzez I2C albo szeregowy interfejs peryferyjny do routingu do usługi chmury obliczeniowej.
Lokalne ASR: kiedy nie ma dostępu do chmury.
Do tej pory dyskusja dotyczyła rozpoznawania mowy w chmurze. Ale co jeśli użytkownik chce kontrolować światła albo temperaturę jacuzzi, kiedy nie ma dostępu do Alexy jako serwisu głosowego opartego o chmurę? Będą też przypadki użycia, kiedy nie ma połączenia z Internetem: to oznacza, że rozpoznawanie mowy musi być wykonane lokalnie.
Bez dostępu do chmury tracimy dostęp do ogromnych możliwości sztucznej inteligencji, która stanowi podstawę działania rozpoznawania mowy. Podczas rozpoznawania mowy lokalnie inteligentny głośnik ogranicza się do słownictwa zawierającego maksymalnie 20 krótkich zdań. Jednakże jest to akceptowalne ze względu na wygodę użytkownika, który jest w stanie zapamiętać tylko ograniczoną liczbę poleceń dla zastosowań domowych.
Rozmaite firmy specjalizują się w danej technologii: będą współpracować z producentami wyposażenia, by opracowywać niestandardowe frazy poleceń, które mogą zostać załadowane do audio DSP albo MCU.
Zastosowania oprócz inteligentnego głośnika
W tym artykule dyskusja skupia się na inteligentnych głośnikach. Pomijając smartfony i inteligentne urządzenia, programiści powinni rozważyć, czy w przyszłości mowa będzie interfejsem człowiek- maszyna (HMI) dla znacznie szerszej gamy produktów. Użytkownicy mają przyciski i przełączniki od wieków: w ciągu ostatniej dekady mobilne urządzenia iPad® i iPhone® od Apple wprowadziły kompletnie nowy sposób łączenia się z elektroniką. Klienci teraz oczekują, by urządzenie z interfejsem HMI dostarczało płynnych wrażeń z ekranu dotykowego.
To samo zjawisko dotyczy mowy: inteligentne głośniki mnożą się w niespotykanym tempie, a sami klienci będą oczekiwać bezpośredniej interakcji z urządzeniami za pomocą mowy. Postęp w dziedzinie rozpoznawania mowy pozwolił na użycie poleceń w nowoczesnych HMI. Technologia jest obecnie gotowa na masową adaptację. To najbardziej naturalny HMI dla wielu produktów i systemów. Programiści i menadżerowie ds. produktu muszą zastanowić się, jak mogą wykorzystać tę technologię, aby zwiększyć popyt na ich kolejny produkt.
 Grzegorz Kamiński: Dlaczego powstały tranzystory FinFET i GAAFET?
Grzegorz Kamiński: Dlaczego powstały tranzystory FinFET i GAAFET?  Google stawia na fuzję jądrową. AI potrzebuje coraz więcej energii
Google stawia na fuzję jądrową. AI potrzebuje coraz więcej energii  Fotowoltaika perowskitowa: od wydajności laboratoryjnej do masowej komercjalizacji
Fotowoltaika perowskitowa: od wydajności laboratoryjnej do masowej komercjalizacji 

![O konkursie organizowanym przez firmę TRUMPF Huettinger i polskie uczelnie techniczne opowiada Alicja Peresada i prof. Jacek Rąbkowski oraz kilkoro nagrodzonych dyplomantów: mgr inż. Jakub Dobosz, inż. Maja Zielińska, dr inż. Jakub Kołodziej, dr inż Weronika Hryniewska-Guzik i dr inż. Grzegorz Bartyzel. Zapraszamy do obejrzenia filmu! [materiał redakcyjny]](https://mikrokontroler.pl/wp-content/uploads/2026/07/TRUMPF-czolowka.png "https://www.youtube.com/watch?v=XkeyLmtLfxo")



