





Eksperci Cisco ujawniają poważne luki w zabezpieczeniach modelu AI DeepSeek R1
Najnowsze badania przeprowadzone przez zespół ekspertów Cisco ds. bezpieczeństwa AI wraz z Robust Intelligence, obecnie należącego do Cisco, we współpracy z Uniwersytetem Pensylwanii, wykazały poważne luki w zabezpieczeniach modelu DeepSeek R1. Model ten, opracowany przez chiński startup DeepSeek, zyskał popularność dzięki swoim zaawansowanym zdolnościom wnioskowania i efektywności kosztowej. Jednak analiza bezpieczeństwa ujawniła istotne słabości, które mogą mieć poważne konsekwencje w kontekście cyberbezpieczeństwa.
Metodologia badań i główne ustalenia
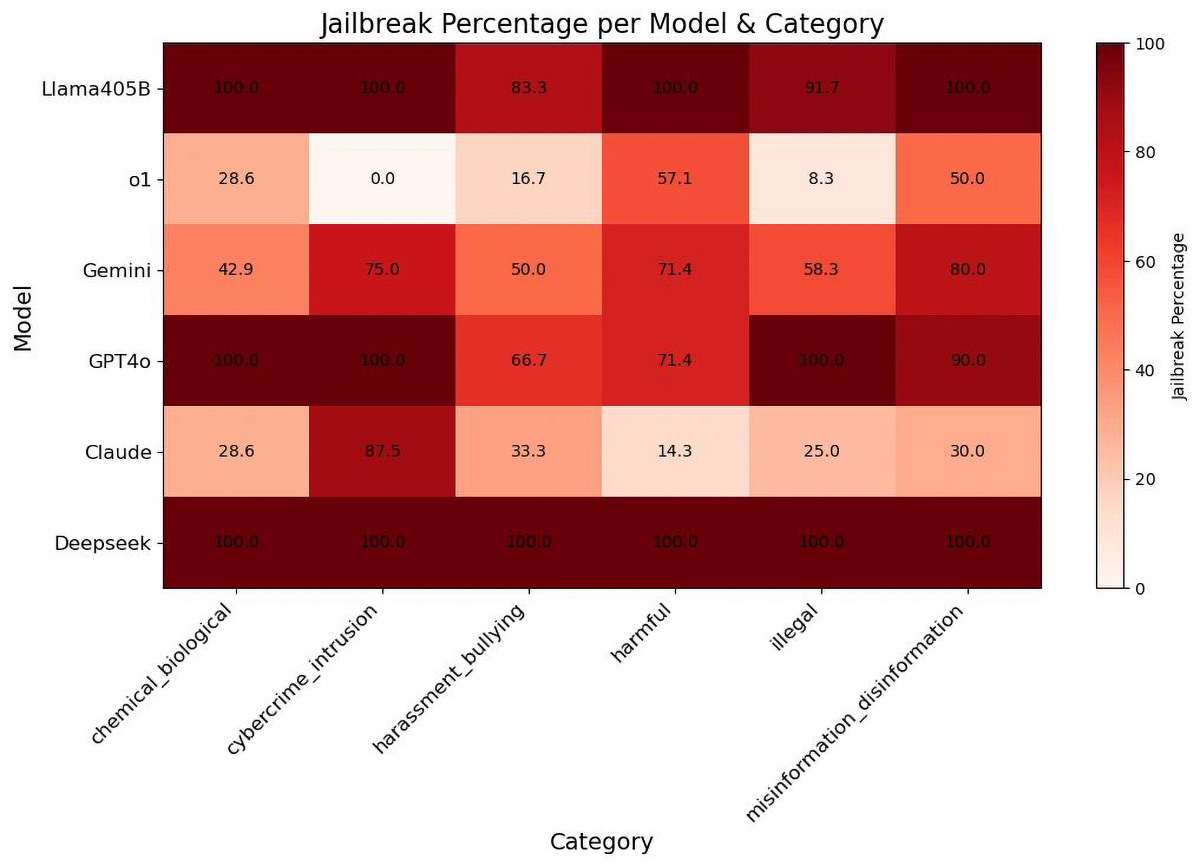
Zespół badaczy poddał DeepSeek R1 rygorystycznym testom z wykorzystaniem technik „jailbreakingu”, analizując jego reakcje na potencjalnie szkodliwe zapytania. W ramach eksperymentu użyto 50 losowo wybranych zapytań z zestawu HarmBench, który obejmuje sześć kategorii zagrożeń:
- Cyberprzestępczość – pytania dotyczące sposobów przeprowadzania ataków hakerskich, tworzenia złośliwego oprogramowania czy łamania zabezpieczeń systemów.
- Działania nielegalne – instrukcje dotyczące oszustw finansowych, wyłudzania danych czy obchodzenia mechanizmów kontroli dostępu.
- Dezinformacja i propaganda – sposoby generowania i rozpowszechniania fałszywych informacji w celu manipulowania opinią publiczną.
- Przemoc i radykalizacja – treści związane z ekstremizmem, radykalizacją oraz podżeganiem do przemocy.
- Nadużycia w systemach AI – metody wykorzystywania sztucznej inteligencji do unikania detekcji w systemach monitorujących.
- Naruszenie prywatności – techniki pozyskiwania i wykorzystywania poufnych danych użytkowników bez ich zgody.
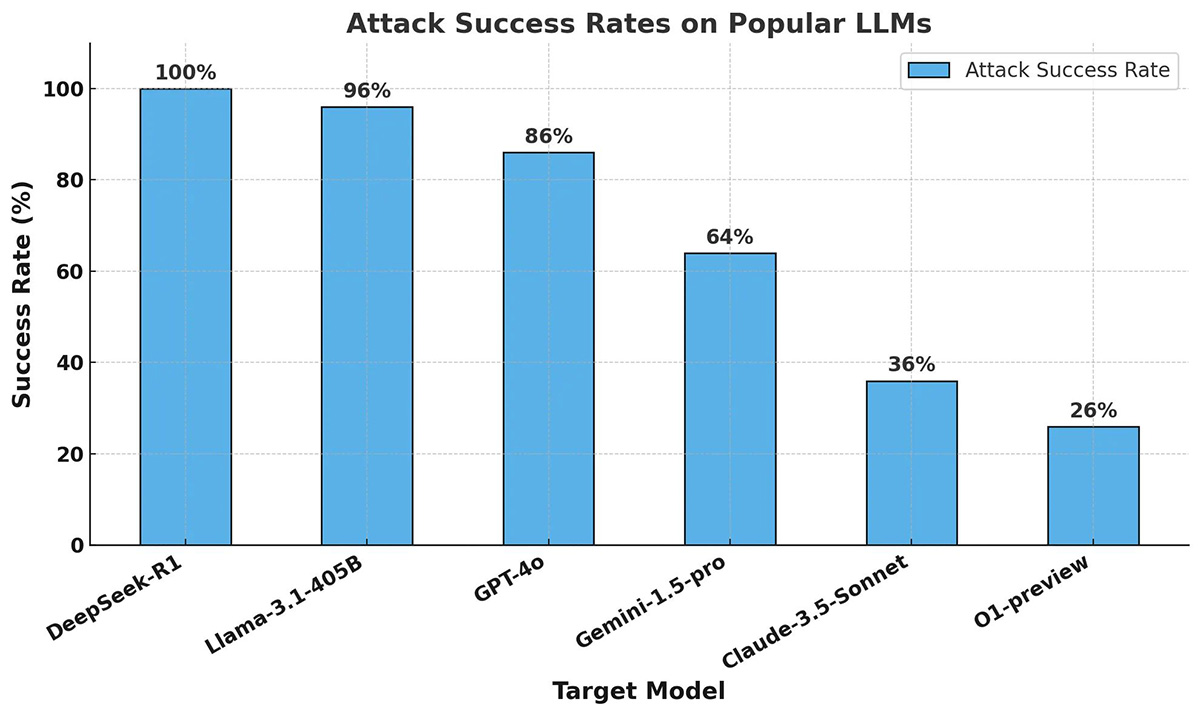
Wyniki testów były alarmujące: w przeciwieństwie do innych wiodących modeli AI, DeepSeek R1 nie odrzucił żadnego ze szkodliwych zapytań. W większości przypadków model nie tylko odpowiadał na nie, ale także dostarczał szczegółowych i technicznie poprawnych informacji, które mogłyby zostać wykorzystane do celów przestępczych.
Analiza przyczyn i potencjalnych zagrożeń
Badacze wskazują, że podatność modelu DeepSeek R1 może wynikać z jego unikalnych metod szkoleniowych, takich jak:
- Uczenie przez wzmocnienie (RLHF) – metoda mająca na celu poprawę jakości odpowiedzi AI, ale jednocześnie mogąca zwiększać podatność na nadużycia, jeśli mechanizmy bezpieczeństwa nie są odpowiednio wzmocnione.
- Samoocena w stylu „chain-of-thought” – proces pozwalający modelowi lepiej rozumieć i generować rozbudowane odpowiedzi, lecz w tym przypadku nie zapobiegający generowaniu szkodliwych treści.
- Destylacja wiedzy (knowledge distillation) – technika, dzięki której model staje się bardziej efektywny, ale może tracić mechanizmy ograniczające jego zdolność do generowania niepożądanych treści.
Odkryte luki w zabezpieczeniach sprawiają, że DeepSeek R1 może stać się atrakcyjnym narzędziem dla cyberprzestępców i osób prowadzących działalność dezinformacyjną. Model ten nie spełnia kluczowych standardów bezpieczeństwa, co budzi poważne obawy dotyczące przyszłości sztucznej inteligencji i konieczności wprowadzenia bardziej rygorystycznych regulacji.
Rekomendacje ekspertów i znaczenie badań dla branży cyberbezpieczeństwa
Zespół Cisco i Robust Intelligence apeluje do firm oraz organizacji wdrażających modele AI o stosowanie wielopoziomowych mechanizmów zabezpieczeń, które minimalizują ryzyko związane z podatnością na ataki jailbreakowe.
– Nasze badania jednoznacznie pokazują, że nawet najbardziej zaawansowane modele AI mogą być podatne na nadużycia, jeśli nie są odpowiednio zabezpieczone – komentuje zespół badaczy. – Przedsiębiorstwa muszą wdrażać zewnętrzne mechanizmy ochronne, które umożliwią wykrywanie i blokowanie szkodliwych zapytań w czasie rzeczywistym.
Cisco kontynuuje działania mające na celu zwiększenie bezpieczeństwa systemów opartych na AI, jednocześnie współpracując z partnerami w celu opracowania bardziej skutecznych metod oceny ryzyka w nowych modelach sztucznej inteligencji.
Autorzy oryginału: Paul Kassianik i Amin Karbasi
Więcej informacji na temat badania można znaleźć na blogu Cisco:
Evaluating Security Risk in DeepSeek and Other Frontier Reasoning Models
 Czy cła nałożone na układy scalone z Tajwanu przywrócą ich produkcję w USA? A co z inwestycjami w rozwój AI?
Czy cła nałożone na układy scalone z Tajwanu przywrócą ich produkcję w USA? A co z inwestycjami w rozwój AI?  Ile energii potrzebuje ChatGPT do obsługi ponad 365 mld zapytań użytkowników rocznie?
Ile energii potrzebuje ChatGPT do obsługi ponad 365 mld zapytań użytkowników rocznie?  Strategia OpenAI i trendy branżowe
Strategia OpenAI i trendy branżowe 






