





Dokąd zmierzamy … w technologiach półprzewodnikowych? Czy prawo Moore’a dalej będzie obowiązywać?
Zawsze, kiedy już wiem o czym chcę napisać, to pojawia się dylemat odnośnie tytułu. Jest to dość trudne, bo byłoby dobrze, gdyby tytuł właściwie oddawał treść. Nie inaczej miałem i tym razem. W pewnym momencie pomyślałem o sformułowaniu “Dokąd zmierzamy?” . To słynne zdanie pochodzi z tytułu obrazu Paula Gauguina pt. „Skąd przychodzimy? Kim jesteśmy? Dokąd zmierzamy?” z lat 1897–1898. W oryginale to “D’où venons-nous? Que sommes-nous? Où allons-nous?” , no ale nie znam francuskiego więc nawet nie wiem jak się to czyta. Obraz poniżej przedstawia alegoryczne podsumowanie przemyśleń artysty o życiu, egzystencji i ludzkiej kondycji. Gauguin zalecał, by obraz czytać od prawej do lewej, rozpoczynając od śpiącego dziecka (narodziny), przechodząc przez młodych ludzi (życie) i kończąc na starej kobiecie (zbliżająca się śmierć).

Paul Gauguin: Skąd pochodzimy? Kim jesteśmy? Dokąd zmierzamy? Museum of Fine Arts, Boston
Obraz jest bardzo duży, a w technologiach półprzewodnikowych staramy się by cegiełki, czyli tranzystory MOSFET, z jakich są w większości zbudowane nasze układy scalone, były jak najmniejsze. No to zastanówmy się, dokąd zmierzamy w technologiach półprzewodnikowych.
Prawo Moore’a i czy będzie dalej obowiązywać?
Najprościej na to pytanie odpowiedzieć: to zależy. Prawo Moore’a to prawo empiryczne, które mówi, że liczba tranzystorów w układzie scalonym podwaja się co około dwa lata przy jednoczesnym utrzymaniu kosztów na podobnym poziomie lub ich spadku. Sformułowane zostało przez Gordona Moore’a w 1965 roku, współzałożyciela firmy Intel. Przedstawia je rysunek poniżej. Widać na nim, że na jednym układzie scalonym przekroczyliśmy już liczbę 50 mld tranzystorów. Postęp związany jest z dalszym rozwojem technologii wytwarzania scalonych układów krzemowych.
Prawo Moore’a i jego graficzna ilustracja. Źródło: Wikipedia
Mimo, że zaczęliśmy używać innych materiałów półprzewodnikowych – mówimy o rozwoju fotonicznych układach scalonych (PIC) – to żadna z nowych technologii nawet nie zbliżyła się i nie zbliży w ciągu najbliższej dekady do poziomu technologii półprzewodnikowej bazującej na krzemie. Są już publikacje mówiące, że już teraz prawo Moore’a nie obowiązuje.
Tak jak napisałem wcześniej, to to zależy, ale przede wszystkim trzeba wyjaśnić, co rozumiemy pod pojęciem układ scalony.
Argumenty za tym że prawo Moore’a już nie obowiązuje lub zaraz przestanie obowiązywać
Gdy spojrzymy na rozwój technologii określony przez minimalny wymiar charakterystyczny, to prawo Moore’a musi przestać obowiązywać. Rysunek poniżej przedstawia mapę drogową dla technologii wg. imac:
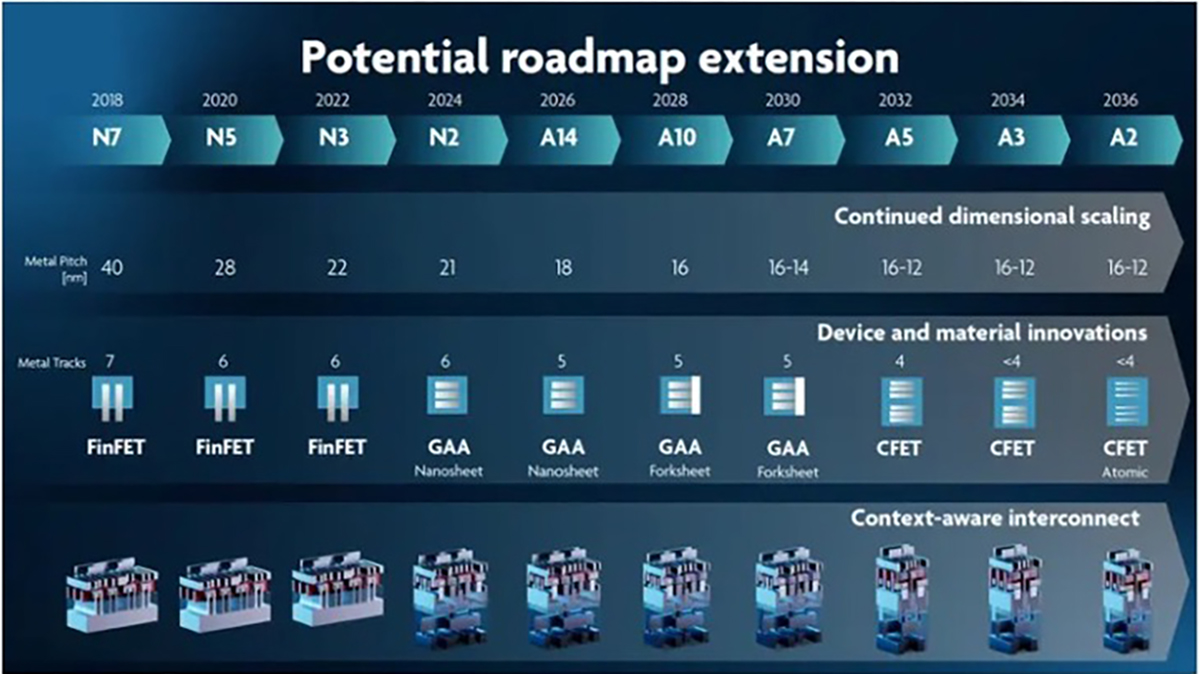
Mapa drogowa rozwoju technologii półprzewodnikowych wg. imac
Jeżeli założymy że obecny poziom technologiczny to 2 nm, czyli technologia N2, to następny wg. imac będzie A14 ( 1,4nm = 14Å, gdzie Å to jednostka zwana Angstrem 1 nm = 10Å).
Dla technologii N2 największe chipy mają powierzchnię ponad 6 cm2. Aby utrzymać prawo Moore’a, powierzchnia chipu musi wzrosnąć do ponad 8,4 cm2. Dla kolejnej technologii A10 (10Å ) powierzchnia chipu wyniesie już znacznie ponad 8,6 cm2. Dlaczego to takie istotne? W najbardziej zaawansowanych układach scalonych, szczególnie tych stosowanych w centrach danych i sztucznej inteligencji (AI), powierzchnia krzemu wymagana do uzyskania pożądanej funkcjonalności na pojedynczym chipie może zbliżać się lub przekraczać limit współczesnego sprzętu fotolitograficznego. Maksymalna powierzchnia naświetlania wynosi bowiem 26 × 33 mm. Oznacza to, że pojedynczy monolityczny chip zazwyczaj nie może być wyprodukowany w rozmiarze większym niż około 858 mm² = 8,6 cm2. Powyżej tego progu integracja monolityczna staje się niemożliwa do zrealizowania. Nikt nie zdecyduje się na zmiany w sprzęcie do naświetlania. Jest on tak skomplikowany i kosztowny że takie modyfikacje nie są raczej możliwe.
Stawia to pod znakiem zapytania sens opracowywania kolejnych technologii, takie jak A7, A5, A3 i A2. Moim zdaniem nastąpi spowolnienie tego trendu i raczej w 2036 roku nie zobaczymy technologii A2 (2Å ). Tym bardziej, że już od A5 będziemy mieć inne problemy wynikające ze struktury krystalograficznej kryształu krzemu.
Kryształ krzemu
Odległość w sieci krystalicznej krzemu, która ma strukturę diamentu (tzw. sieć typu diamentowego), wynosi około 0,543 nm (5,43 Å), co jest długością krawędzi jego komórki elementarnej. W tej strukturze każdy atom krzemu jest połączony wiązaniami kowalencyjnymi z czterema innymi atomami, tworząc sieć opartą na czworościanach foremnych tzw. tetraedrach.
Dla technologii A5 wymiar charakterystyczny będzie równy wymiarowi pojedynczego kryształu krzemu. Nie bardzo wyobrażam sobie, jak miałyby być definiowane technologie A3 i A2. Przy A2 na rysunku z imac jest uwaga “Atomic” przy strukturze tranzystora. Jak to rozumieć nie wiem, ale wchodzimy już praktycznie w odległości atomowe.
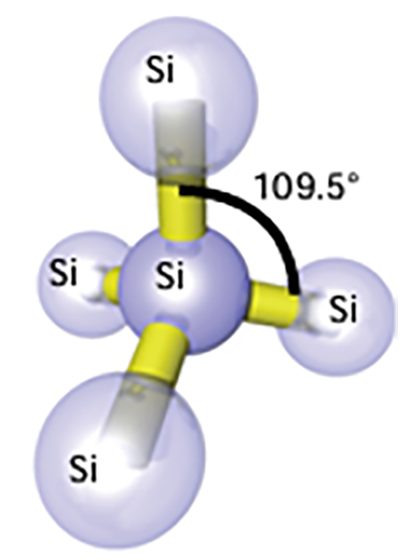
Struktura pojedynczego tetraedru kryształu krzemu
Odległość centrów dwóch sąsiednich atomów Si wynosi tylko 2,35 Å, tak więc dla technologii A2 i A3 nawet cały kryształ byłby większy od wymiaru charakterystycznego dla tej technologii.
Aby zbudować sieć o strukturze diamentu w ortogonalnym układzie współrzędnych, w którym wszystkie trzy główne osie są prostopadłe do siebie, rozpoczyna się sieć sześcienną centrowaną na powierzchni. Jak to pokazano na rysunku poniżej, gdzie atomy zajmują wszystkie narożniki i środki boków pociętej na sześciany komórki elementarnej, o długości krawędzi 5,43 Å. Czerwone linie odniesienia nie odpowiadają stosunkom wiązań atomów, lecz krawędziom komórek elementarnych. Kopia tej sieci (zielone linie odniesienia oznaczają krawędzie komórek elementarnych) jest teraz „zintegrowana” z pierwszą siecią we wszystkich trzech kierunkach przestrzennych, przesunięta o jedną czwartą długości tej krawędzi. Łącząc każdy atom z czterema najbliższymi sąsiadami (na rysunku żółte linie oznaczają wiązania Si-Si) i ukrywając krawędzie komórek elementarnych, uzyskuje się ostatecznie strukturę diamentowej sieci krzemu, w której każdy atom krzemu tetraedrycznie wiąże cztery kolejne atomy krzemu, jak pokazano wcześniej.
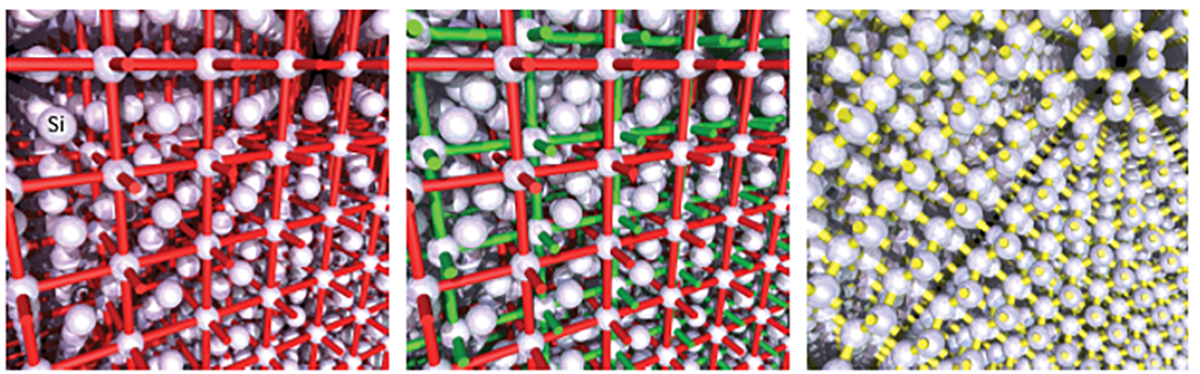
Sieć krystalograficzna monokryształu krzemu. Źródło: Merck
Na rysunku poniżej można zobaczyć strukturę jednej komórki monokryształu krzemu.
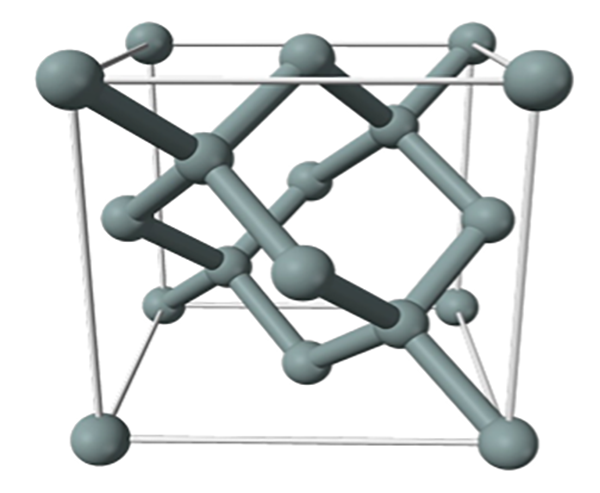
Sieć krystalograficzna pojedynczej komórki monokryształu krzemu. Źródło: Semiconductor Devices: Theory and Applications, autor James M. Fiore , 2021
Nie będę już tego bardziej komplikował, ale już teraz zbliżamy się do wymiaru limitu sieci, bo przecież dla technologii N2 mamy wymiar charakterystyczny technologii tylko ok. 4 x wymiar pojedynczej komórki elementarnej monokryształu krzemu (4 x 5,43 Å).
Uzysk
Aby być w zgodzie z prawem Moore’a, wraz postępem technologicznym i ze wzrostem skomplikowania układu scalonego, rośnie też jego powierzchnia. Jak już wspomniałem, dla technologii A10 powierzchnia najbardziej zaawansowanych układów scalonych osiągnie limit techniczny urządzeń do fotolitografii. Tak dużych układów nie da się produkować na obecnie istniejących maszynach do naświetlania fotorezystu. Jednakże, wraz ze wzrostem powierzchni układu, spada także uzysk. W kontekście produkcji układów scalonych, jest to stosunek działających chipów do całkowitej liczby wyprodukowanych, po przejściu przez cały proces technologiczny i testy.
Specyfiką produkcji układów scalonych jest fakt, że nie ma takiej możliwości, by wszystkie chipy na płytce były sprawne funkcjonalnie i parametrycznie po przejściu całego procesu technologicznego. W trakcie procesu powstają defekty, które uszkadzają chipy. Źródłem tych defektów są same procesy technologiczne, maszyny i zanieczyszczenia. By zminimalizować wpływ zanieczyszczeń na uzysk, układy scalone produkuje się w Clean roomach, gdzie liczba zanieczyszczeń w powietrzu jest bardzo mała. Ale nawet te wszystkie działania, by zminimalizować defekty w produkcji układów scalonych, nie prowadzą do ich całkowitego wyeliminowania. Więcej na temat uzysku i przyczyn powstawania defektów można znaleźć w podręczniku z 2006 roku “Fundamentals of Semiconductor Manufacturing and Process Control, autorstwa Gary S. May, Ph.D. Georgia Institute of Technology Atlanta, Georgia, Costas J. Spanos, Ph.D. University of California at Berkeley Berkeley, California w którym temu zagadnieniu jest poświęcony cały rozdział 5.
Uzysk, który jako zależny od wielu czynników, obliczany jest przy pomocy modeli statystycznych. Producenci podzespołów półprzewodnikowych muszą obliczać uzysk nie tylko z powodów ekonomicznych, by określić koszty produkcji, ale także z powodów logistyczno-handlowych. Przyjmując zamówienia na dostawę 100 tysięcy sztuk danego układu scalonego, producent musi określić, ile sztuk musi wyprodukować, aby zrealizować zamówienie. Gdy uzysk jest np. 70%, to trzeba wyprodukować prawie 143 tysięcy sztuk. To bardzo ważne, by wiedzieć, jaki jest dokładnie uzysk dla danego układu scalonego i technologii. Gdyby uzysk został zaniżony, to trzeba by było wyprodukować więcej podzespołów niż jest w zamówieniu, co skutkowałoby marnowaniem mocy produkcyjnych. Było to szczególnie ważne w latach niedoboru dostaw.
Takich dylematów nie mają np. producenci samochodów. Zamówienie na 1000 sztuk oznacza konieczność wyprodukowania 1000 szt. Jedyny problem, jaki mieli w ostatnich latach, to dostępność układów scalonych i podzespołów dyskretnych dla motoryzacji.
Modele statystyczne pokazują, jak zmienia się uzysk wraz ze wzrostem powierzchni układu scalonego (rys. poniżej ). „D0” to liczba defektów i przyjmuje się, że wynosi on 0.4 defektu/cm2 dla dobrze opanowanej technologii. Wiodące firmy produkujące układy scalone podają, że w ich fabrykach D0 = 0.1 defektu/cm2. Przy D0 = 0.1 defektu/cm2 dla maksymalnej powierzchni chipu 8.58 cm2, uzysk wynosi ponad 42%. Dane są podane dla tzw. rozkładu/modelu Poisson’a. Zakłada się, że model ten jest dobry dla relatywnie małych chipów i prostszych technologii. Dla określenia uzysków dla większych i bardziej zaawansowanych chipów zbudowano inne modele np. model Seeds’a.
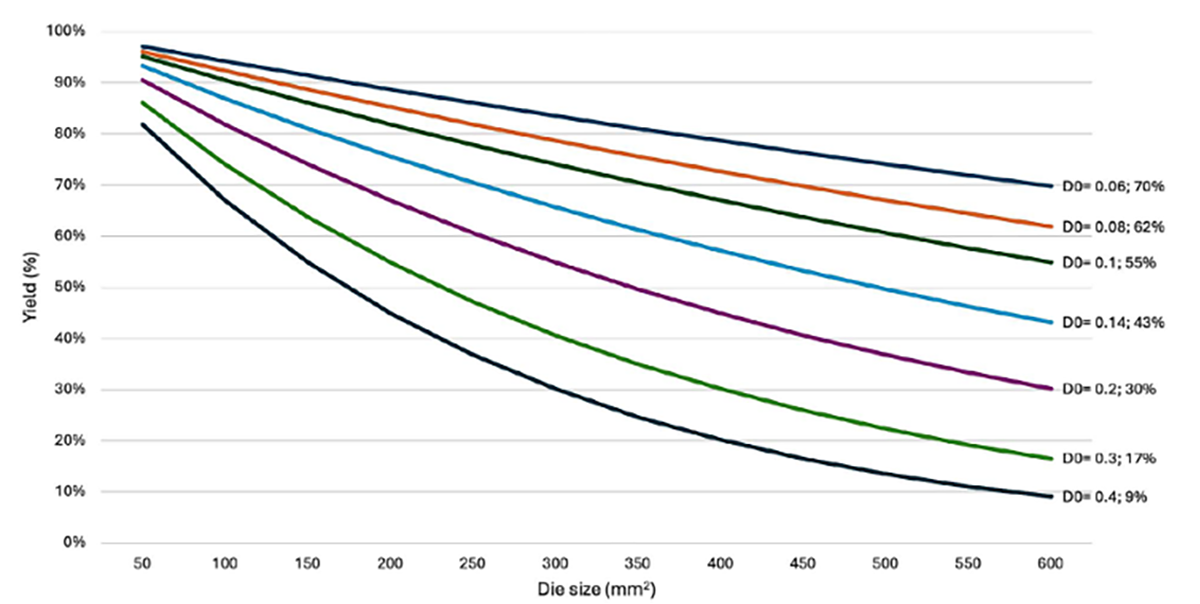
Wraz ze wzrostem powierzchni chipu, uzysk układów scalonych monolitycznych spada (D0 = gęstość defektów). Źródło: IC-Link by imec
Dla tego modelu przy D0 =0.1 defektu/cm2 uzysk wyniesie prawie 54%. Ale już dla D0=0.4 defektu/cm2 uzysk wyniesie już tylko nieco ponad 22%, a to jest zbyt mały, by produkcja była opłacalna. Dla porównania, w modelu Poisson’a uzysk byłby tylko 3,2%.
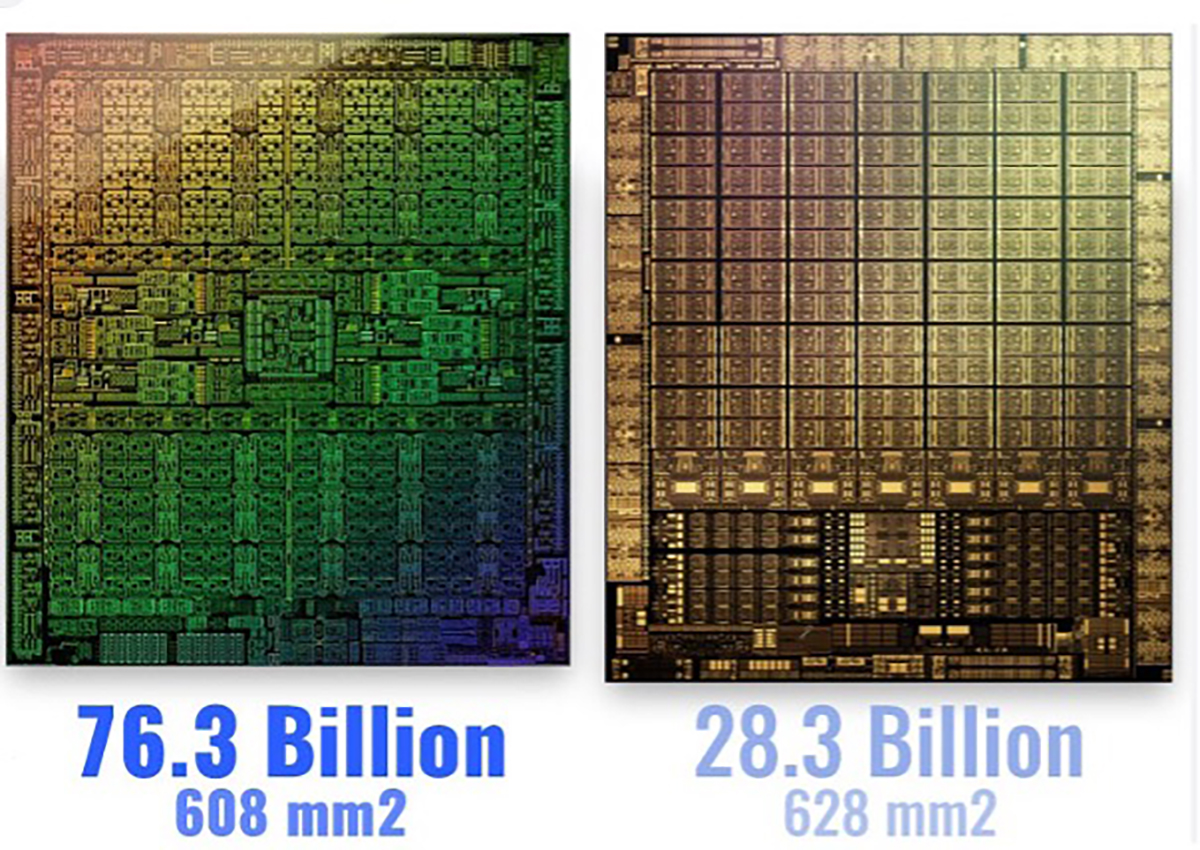
Zdjęcia chipów procesorów dla kart graficznych. Z lewej: RTX4000; z prawej: RTX3060
Szacowany uzysk wg. różnych modeli dla procesora karty graficznej RTX4000, wykonanego w technologii N5 (5nm, TSMC) przedstawia rysunek poniżej:
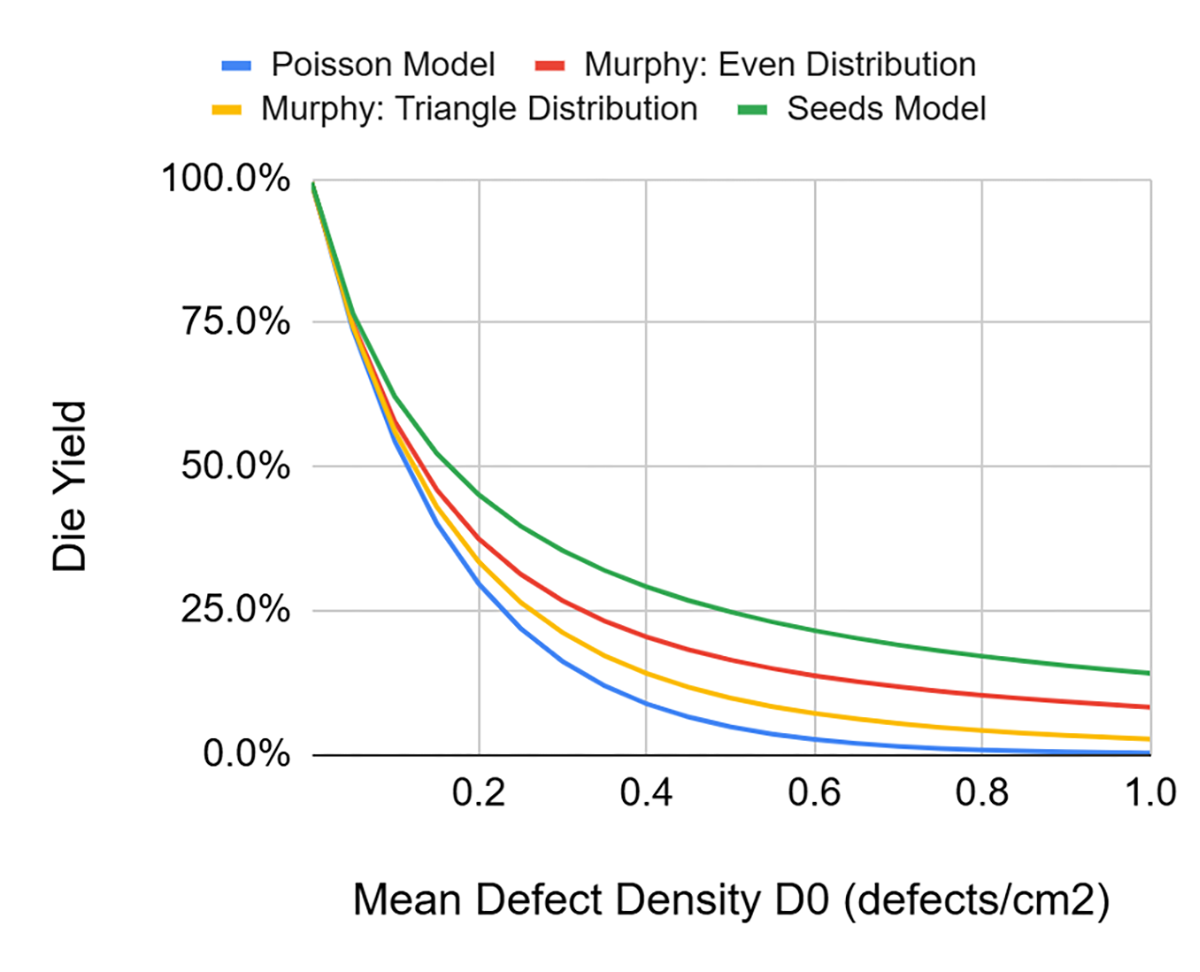
Szacowany uzysk wg. różnych modeli dla procesora karty graficznej RTX4000 wykonanego w technologii N5 (5nm, TSMC) w funkcji gęstości defektów D0.
Dla dużych układów z duża liczbą procesów fotolitografii, opracowano inny model. Uwzględniono liczbę defektów na liczbę krytycznych warstw/fotolitografii i przyjęto parametr DD = liczba defektów na cal kwadratowy i na warstwę krytyczną. Dla technologii 5 nm przyjęto, że liczba warstw krytycznych wynosi 35.5, wyliczone wg. modeli statystycznych.
Ten model nazwano modelem Bose-Einsteina. Uzysk dla wspomnianego powyżej procesora graficznego wynosi >35%, a więc będzie niższy, niż dla modelu Seeds’a i D0=0.1 defektu/cm2 , jednakże ciągle dobry z punktu widzenia kosztów produkcji.
Uzysk spada wraz ze wzrostem technologii
Przy maksymalnej powierzchni chipu 8.58 cm2 zbliżamy się do 20%, a to za mało by produkcja była opłacalna. Wraz ze wzrostem skomplikowania technologii uzysk będzie spadał i to jest dodatkowy niekorzystny czynnik.
Dlaczego aż tyle miejsca poświęciłem uzyskowi?
Po pierwsze, to bardzo niestandardowy parametr dotyczący produkcji, nie występujący w większości branż związanych z produkcją. Nie ma takich rodzajów działalności, gdzie czasami ⅔ produkcji trzeba wyrzucić do kosza, przy czym nie jest to spowodowane jakąś nieudolnością. Jest to normalne w produkcji układów scalonych.
Po drugie, to niezwykle istotny czynnik z punktu widzenia ekonomiki produkcji podzespołów półprzewodnikowych i jeden z czynników który może ograniczać rozwój. To, że możemy coś zrobić nie oznacza, że to ma sens i jest opłacalne. To czynnik, który może spowodować, że prawo Moore’a przestanie obowiązywać, bo często pamiętamy tylko o pierwszej jego części, czyli o podwojeniu liczby tranzystorów, ale nie o drugiej która mówi “przy jednoczesnym utrzymaniu kosztów na podobnym poziomie lub ich spadku”.
Te wszystkie powyżej poruszone kwestie skłaniają do wnioski, że prawo Moore’a już nie obowiązuje lub zaraz przestanie obowiązywać.
Czemu więc odpowiedziałem na pytanie zwrotem “to zależy” ?
Chiplety i kiedy je stosować zamiast monolitycznych układów scalonych
Wraz z rosnącą popularnością chipletów, projektanci układów scalonych stają przed krytycznym pytaniem: Kiedy należy odejść od projektowania monolitycznego układu scalonego? Czy stosowanie chipletów podtrzyma obowiązywanie prawa Moore’a ? – oczywiście pod warunkiem że chiplet uznamy jako formę układu scalonego.
Czym jest chiplet? AI Googla czy ChatGPT na tak postawione pytanie odpowiada:
Chiplet to wyspecjalizowany układ scalony (IC), który pełni określoną funkcję i jest projektowany tak, aby można go było łączyć z innymi chipletami, tworząc większe i bardziej złożone chipy, takie jak procesory wielordzeniowe lub system-on-chip (SoC). W odróżnieniu od tradycyjnych, monolitycznych układów, które integrują wszystkie funkcje w jednej krzemowej strukturze, chiplety dzielą te funkcje na mniejsze, modułowe części, co zwiększa elastyczność i efektywność produkcji.
Mnie się ta definicja nie podoba, ale jej początek, mówiący o “wyspecjalizowanym układzie scalonym (IC)” sugeruje, że możemy chiplet uważać za jeden układ scalony, mimo iż składa się z wielu monolitycznych chipów. I to sprawia, że dalej do chipletu możemy stosować prawo Moore’a.
Współczesne układy scalone są coraz większe i bardziej skomplikowane. W rezultacie, wytwarzanie wszystkich typowych funkcji wysokowydajnego układu scalonego na jednym kawałku krzemu może wiązać się ze znacznymi kosztami, ryzykiem i brakiem elastyczności. W ciągu ostatnich 10 lat, architektury oparte na chipletach zaczęły zyskiwać popularność na rynku. Zamiast integrować wszystkie komponenty na jednym dużym chipie, system jest podzielony na wiele mniejszych – szerzej nazywanych chipletami – z których każdy jest zoptymalizowana pod kątem określonej funkcji. Chiplety są produkowane oddzielnie, a następnie montowane w jeden pakiet, wykorzystując zaawansowane technologie montażu, takie jak pakowanie 2.5D i lub układanie w stosy w montażu typu 3D.
Wszystkie najbardziej zaawansowane technologiczne firmy pracują nad tymi technologiami montażu np.:
- TSMC – technologia CoWoS,
- Intel – technologia Foveros,
- Samsung – technologia I-Cube.
Dotychczas procesy front-end, w których specjalizowały się foundry, takie jak np. TSMC, były oddzielone od procesów back-end w których specjalizowały się firmy OSAT (Outsource Assembly and Testing) np. firma ASE. Obecnie, jak już wspomniałem, firmy takie jak np. TSMC również zainteresowały się tą technologią.
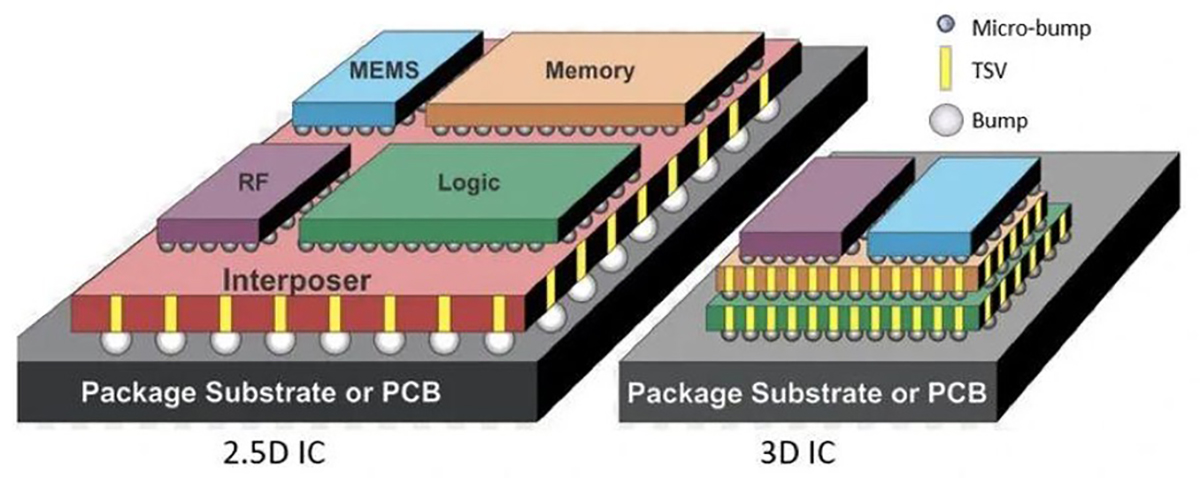
Różnica w montażu chipletu w technologii 2.5D i 3D
Rysunek powyżej odpowiada na pytanie, kiedy stosować chiplety. Jedna z takich sytuacji jest pokazana na rysunku dotyczącym montażu 2.5D, podobna sytuacja – przy zachowaniu tych samych kolorów – pokazana jest na rysunku montażu 3D. Układ RF, np. telekomunikacyjny, wymaga innej technologii niż układ logiki np. procesora. To samo dotyczy pamięci i czujnika MEMS. Wszystkie te układy, aby uzyskać najlepsze parametry, powinny być wykonane w specyficznych i optymalnych dla nich technologiach. Tego nie moglibyśmy uzyskać stosując jeden monolityczny układ scalony. Inna sytuacja jest wówczas, gdy z przyczyn technologicznych i kosztów wytwarzania, lepiej jest wykonać układ scalony jako chiplet. Przykładem jest procesor firmy Apple M1 Ultra ( zdjęcie poniżej) , który składa się z dwóch takich samych układów scalonych M1 Max.

Procesor Apple M1 Ultra. Źródło: materiały prasowe firmy Apple
To przykład gdy wielkość chipu determinowała jego podzielenie na dwa mniejsze. W tym przypadku zastosowanie chipletu spowodowało zapewne zwiększeniu uzysku, co w rezultacie prowadzi do obniżania kosztów wytwarzania całego procesora.
Co zatem sprawia, że ciągle dążymy do zmniejszenia rozmiarów tranzystorów?
Zwiększając przy tym funkcjonalność i wydajność pojedynczego monolitycznego układu scalonego?
Pomimo rosnącego zainteresowania architekturami opartymi na chipletach, monolityczne układy scalone bardzo dużej integracji są nadal preferowane w wielu sytuacjach. Głównym powodem jest prostota architektury: integracja wszystkich funkcjonalności na jednym rdzeniu pozwala uniknąć dodatkowych problemów z projektowaniem, testowaniem i pakowaniem, które wynikają z podziału projektowanego chipu na mniejsze i zamontowanie go w formie chipletu. Co więcej, inżynierowie mają wieloletnie doświadczenie w projektowaniu takich układów i wiedzą, na co zwracać uwagę pod względem weryfikacji i testowania. Mają również dostęp do dojrzałej gamy narzędzi automatyzacji projektowania elektronicznego (EDA), co pomaga ograniczyć trudności związane z rozwojem monolitycznych układów scalonych. Ponadto testowanie jest prostsze. Wszystkie funkcje znajdują się na jednym rdzeniu, więc nie ma potrzeby projektowania testów dla różnych chipów z uwzględnieniem potencjalnych trybów awarii w ich połączeniach. Monolityczne projekty chipów oferują również ścisłą integrację między blokami funkcjonalnymi, minimalizując opóźnienia połączeń. W systemach o ścisłych ograniczeniach czasowych, gdzie niezbędna jest komunikacja o niskim opóźnieniu między ściśle sprzężonymi rdzeniami obliczeniowymi lub między rdzeniami procesora a współdzielonym blokiem pamięci, nawet niewielkie opóźnienia mogą obniżyć wydajność. W takich przypadkach fizyczna bliskość bloków na jednym rdzeniu pozostaje kluczową zaletą.
Wyzwania dotyczące chipletów obejmują ustanowienie standardów dla technologii montażu i zapewnienie długoterminowej niezawodności pod obciążeniem termicznym i mechanicznym.
Testowanie również wymaga innowacji
Chociaż poszczególne chipy wchodzące w skład chipletu są rygorystycznie testowane, mogą nie zachowywać się tak samo po umieszczeniu w obudowie. Dostęp do pojedynczych chipów w celu testowania również może stwarzać trudności, szczególnie gdy struktury krzemowe są umieszczone w stosie 3D.
Jednakże już teraz firmy oferujące narzędzia do projektowania układów scalonych rozpoczęły integrację systemów i implementację nowych norm związanych z chipletami, by ułatwić projektantom projektowanie systemów opartych o chiplety. Przykładem takiego podejścia jest oprogramowanie Innovator3D firmy Siemens EDA ( dawniej Mentor Graphics).
Pojawienie się takiego oprogramowania powinno znacząco poprawić popularność chipletów i zwiększyć ich rozpowszechnienie, ale nie sądzę, by chiplety zdominowały projektowanie nowych, zaawansowanych układów scalonych.
W nadchodzących latach podejścia monolityczne i oparte na chipletach będą nadal współistnieć, a każde z nich będzie wybierane w oparciu o specyficzne wymagania budowanego systemu. To tylko dodatkowa możliwość w projektowaniu układów scalonych.
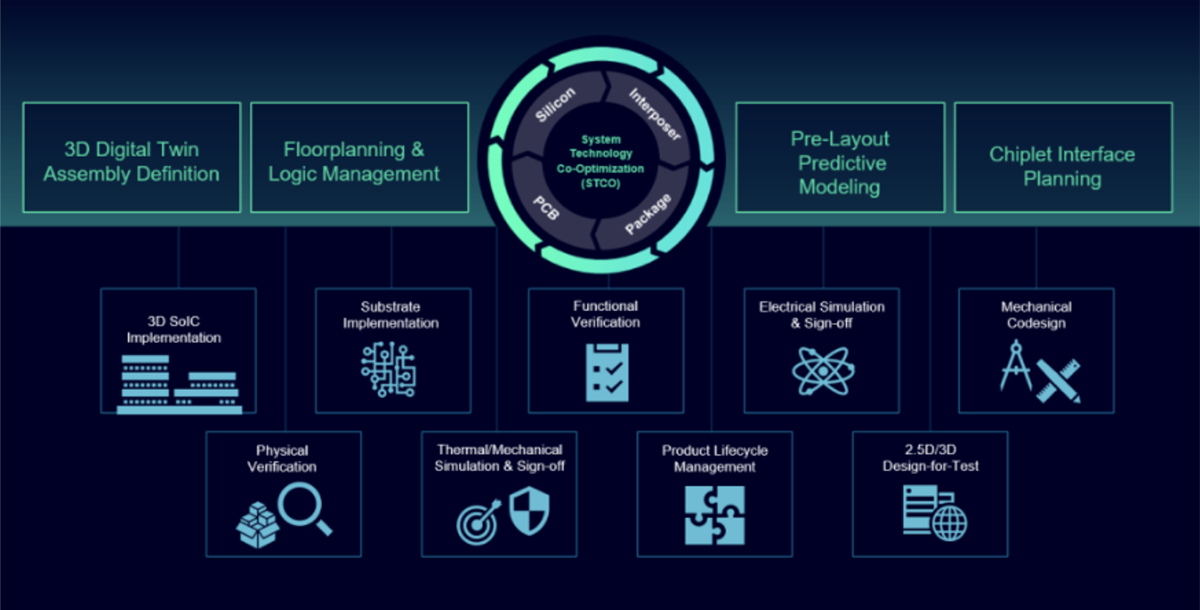
Oprogramowanie Innovator3D IC – widok zintegrowanego kokpitu dla projektanta chipletu w tym z wykorzystaniem montażu 3D. Źródło: materiały firmy Siemens EDA
Jednakże wydaje mi się, że chiplety umożliwią, by prawo Moore’a dalej obowiązywało, o ile uznamy że chiplety są jednym układem scalonym. Czas pokaże czy mam rację.
 Czy diamenty są najlepszym przyjacielem energoelektronika?
Czy diamenty są najlepszym przyjacielem energoelektronika? 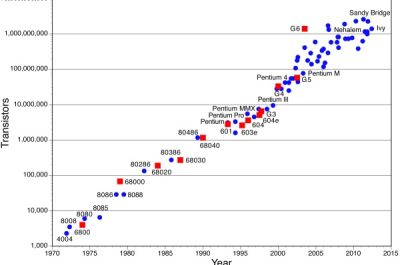 Koniec prawa Moore’a odmienia branżę
Koniec prawa Moore’a odmienia branżę  Grzegorz Kamiński: Wszystko o rynku i podzespołach z węglika krzemu …no prawie wszystko
Grzegorz Kamiński: Wszystko o rynku i podzespołach z węglika krzemu …no prawie wszystko 






