





Kamienie milowe rozwoju sztucznej inteligencji – według prof. Ryszarda Tadeusiewicza
Dużo mówimy i piszemy o sztucznej inteligencji (AI). Wiemy już, jaka ona jest. Przynajmniej tak się nam wydaje. Ale czy wiemy, jak ona powstawała? A warto się tego dowiedzieć, bo dzięki poznaniu owej chronologii lepiej zrozumiemy jej dzisiejszą budowę i wynikające z tego konsekwencje.
Najpierw zobaczymy to na zbiorczym rysunku, na którym zaznaczyłem ważne „kamienie milowe” rozwoju AI.
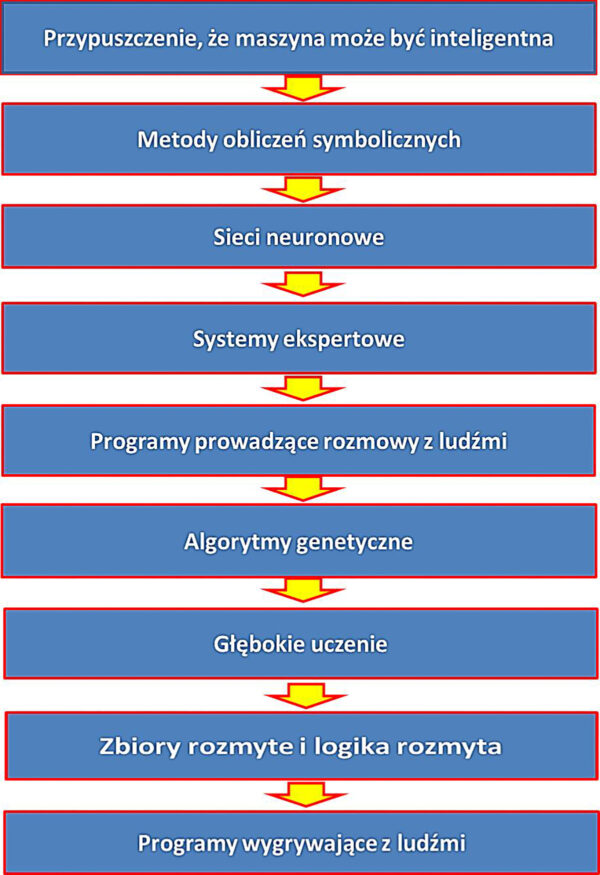
Omówię je skrótowo, odsyłając po szczegóły do mojej książki zatytułowanej „Krótka historia sztucznej inteligencji” która się niebawem ukaże nakładem warszawskiego wydawnictwa RM.
Matematyk Alan Turing w 1949 roku rozważał inteligencję maszyn obliczeniowych
Pierwszym „kamieniem milowym”, od którego się wszystko zaczęło, było wyrażenie publiczne przypuszczenia, że maszyna może być inteligentna. Sformułował je matematyk brytyjski Alan Turing. W 1949 roku, w artykule Computing Machinery and Intelligence (Maszyny obliczeniowe i inteligencja), zaproponował on – jako pierwszy! – pojęcie sztucznej inteligencji. Przewidział argumenty przeciwników tej koncepcji i odpierał ich (antycypowane) ataki proponując między innymi empiryczny sposób sprawdzenia, czy maszyna jest inteligentna – tak zwany test Turinga.
Po tragicznej śmierci Turinga, który popełnił samobójstwo, ponieważ sąd brytyjski skazał go na wykastrowanie, gdy się wydało, że był on homoseksualistą (co w Wielkiej Brytanii było traktowane jak przestępstwo), przez dość długi czas nikt nie podejmował jego koncepcji. Przełom nastąpił, gdy wybitni informatycy (jako pierwsi Newell, Shaw i Simon) wykazali, że komputery mogą wykonywać różne operacje nie tylko na liczbach, ale także na symbolach.
Termin sztuczna inteligencja funkcjonuje od 1956 roku
Program „Logic Theorist” stworzony przez wymienionych wyżej informatyków wywołał sensację, bo potrafił całkiem samodzielnie dowodzić twierdzenia matematyczne, między innymi pochodzące ze słynnego dzieła „Principia Mathematica” Bertranda Russela. To był ten drugi kamień milowy.

Principia Mathematica Whitehead & Russel Volume I-III [2004]; Allegro; Bertrand Arthur William Russell, zdjęcie z 1936 roku; Wikipedia
Koncepcja sieci neuronowych, które uczą się same
Następny kamień milowy związany był koncepcją tak zwanych sieci neuronowych. Badacze tworzący te sieci wyszli ze słusznego założenia, że skoro intelekt człowieka mieści się w jego mózgu, a biolodzy zgromadzili już bardzo dużo konkretnych informacji na temat tego, jak jest zbudowany ludzki mózg i jak działa – to budując techniczny model fragmentu mózgu można otrzymać maszynę zdolną do jego naśladowania, a w szczególności do uczenia się. Pierwszy zbudował taką maszynę Frank Rosenblatt, psycholog zatrudniony w Cornell Aeronautical Laboratory w Buffalo. W 1958 roku opisał, co potrafi ta maszyna (nazwana Perceptronem i przeznaczona do rozpoznawania obrazów).
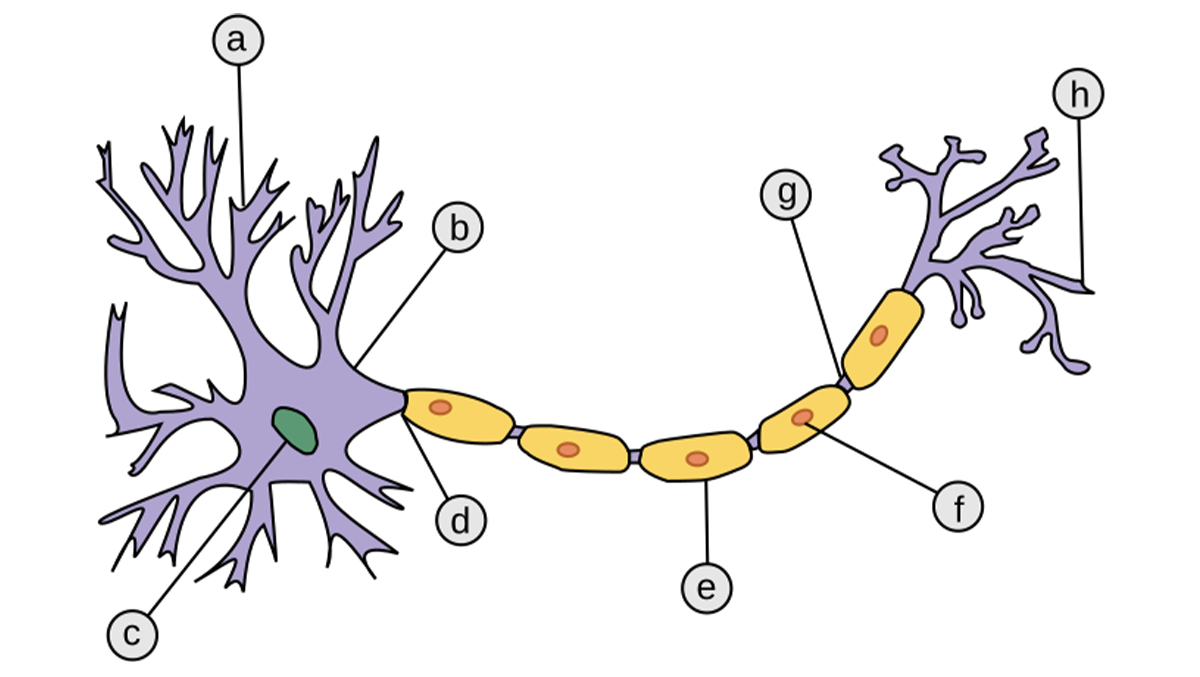
Schemat budowy neuronu: a – dendryty, b – ciało komórki, c – jądro komórkowe, d – akson, e – otoczka mielinowa, f – komórka Schwanna, g – przewężenie Ranviera, h – wiele zakończeń aksonu. Źródło: Wikipedia

Perceptron złożony z jednego neuronu McCullocha-Pittsa: ma n wejść (dendrytów) i 1 wyjście (akson); służy do wykrywania pojedynczej cechy w danych; każda dana jest zapisana w postaci wektora mającego n składowych. Źródło: Wikipedia
Od tej pory tryumfalny pochód coraz doskonalszych sieci neuronowych wyznaczał najważniejszy kierunek rozwoju sztucznej inteligencji. Przy czym rozwój sieci neuronowych jako narzędzia sztucznej inteligencji polegał na doskonaleniu metod ich uczenia. To był (i jest!) klucz do sukcesu. Użytkownicy sieci neuronowych bardzo cenią fakt, że zamiast samemu wymyślać sposób rozwiązania jakiegoś problemu, wystarczy sieci neuronowej pokazać (w ramach tak zwanego zbioru uczącego) kilka prawidłowo rozwiązanych zadań, a sieć sama się nauczy, jak te zadania trzeba rozwiązywać. Co więcej – sieć potrafi zdobytą wiedzę uogólniać. Nauczona na pewnym zbiorze przykładów rozwiązuje skutecznie także zadania odmienne od tych, na których była uczona, ale w jakiś sensie podobne. Sieci neuronowe okazały się bardzo dobrym narzędziem sztucznej inteligencji, więc na całym świecie powstało ich dosłownie miliony do różnych celów, a ukoronowaniem „kariery” było przyznanie w 2024 roku aż czterech Nagród Nobla badaczom, którzy najbardziej przyczynili się do ich rozwoju. Badaczami tymi byli Geoffrey Hinton i John Hopfield w dziedzinie fizyki oraz Demis Hassabis i John Jumper w dziedzinie chemii.
Porady eksperckie dla „zwykłych ludzi” już w 1966 roku
Kolejny „kamień milowy” został położony, gdy badacze sztucznej inteligencji przestali się zajmować głównie naukowymi badaniami możliwości maszyn wyposażonych w oprogramowanie wyposażające je w możliwości inteligentnych zachowań, a zamiast tego pochylili się nad potrzebami zwykłych ludzi. Sięgnęli w związku z tym do systemów technicznych, które mogły doradzać ludziom w różnych ich potrzebach, czyli pełnić w określonych obszarach funkcję mądrego eksperta – stąd ich nazwa „Systemy ekspertowe”. Jako pierwszy koncepcję takiego wykorzystania inteligentnego komputera zaproponował w 1965 roku Edward Feigenbaum. Koncepcja ta polegała na tym, że w komputerze umieszcza się w odpowiedniej formie wiedzę pozyskaną od ekspertów, a wbudowany w program system automatycznego wnioskowania potrafi tę ogólną wiedzę ekspertów zamienić na radę lub sugestię przekazywaną użytkownikom w odpowiedzi na ich zapytania.

Edward Feigenbaum (siedzący), dyrektor Centrum Obliczeniowego Uniwersytetu Stanforda, wraz z członkami zarządu Centrum Obliczeniowego w 1966 r. Źródło: Forbes
Pierwszy system ekspertowy o nazwie DENDRAL został zbudowany w 1966 roku przez Feigenbauma oraz Bruce’a G. Buchanana. Pomagał on chemikom w identyfikacji nieznanych cząsteczek organicznych. W 1970 został stworzony na Uniwersytecie Stanforda systemem MYCIN. System ten przeznaczony był początkowo do wspomagania diagnostyki zakażeń krwi i optymalizacji antybiotykoterapii. Potem powstało mnóstwo innych systemów ekspertowych dla różnych dziedzin i są one stosowane z powodzeniem do dziś.
DENDRAL – jeden z pierwszych systemów eksperckich, opracowany od 1965 roku przez badacza sztucznej inteligencji Edwarda Feigenbauma i genetyka Joshuę Lederberga, obaj z Uniwersytetu Stanforda w Kalifornii.
Terapia u ELIZY
Bardzo istotnym „kamieniem milowym” w rozwoju sztucznej inteligencji było stworzenie programów prowadzących inteligentne rozmowy z ludźmi. Pierwszy program prowadzący niebanalny dialog z człowiekiem powstał w 1964 roku. Zbudował go profesor MIT Jeseph Weizenbaum z Massachusetts Institute of Technology (MIT). Program ten nazywał się ELIZA i mógł rozmawiać z człowiekiem na różne tematy. Rozmowa toczyła się za pomocą dalekopisu, więc rozmawiający człowiek mógł nie wiedzieć, że rozmawia z maszyną. Nazwa ELIZA pochodziła ze sztuki George Bernarda Shawa zatytułowanej Pigmalion, w której profesor fonetyki Henry Higgins uczy wytwornego posługiwania się językiem prostą kwiaciarkę z Covent Garden, noszącą właśnie imię Eliza.
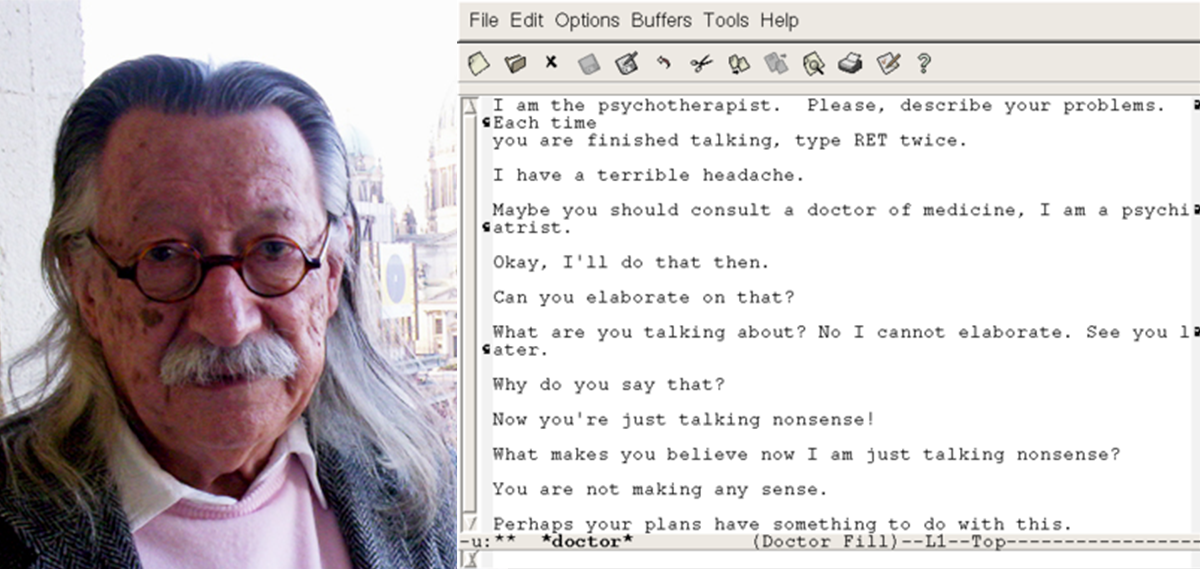
Joseph Weizenbaum, zdjęcie z 2005 roku. Źródło: Wikipedia; po prawej: Eliza – program symulujący psychoanalityka, napisany w 1966 przez Josepha Weizenbauma za pomocą języka SLIP
Z programem ELIZA można było rozmawiać na dowolny temat, ale największym powodzeniem cieszył się scenariusz DOCTOR, w którym program udawał psychoterapeutę skłaniającego korzystającego z jego usług człowieka do zwierzania się ze swoich problemów emocjonalnych. Mimo w sumie bardzo prostej budowy, program zbierał liczne pochwały od użytkowników. Program ELIZA był jednym z pierwszych chatterbotów (jak ChatGPT współcześnie).
Pierwsze algorytmy genetyczne i podejmowanie decyzji
Ciekawy zwrot w dziedzinie sztucznej inteligencji miał miejsce gdy wynaleziono pierwsze algorytmy genetyczne, które występują w mojej opowieści jako kolejny „kamień milowy”. Jednym z zadań, które rozwiązuje się z wykorzystaniem metod sztucznej inteligencji, jest problem optymalnego podjęcia decyzji w złożonej sytuacji. Matematycy wymyślili mnóstwo metod optymalizacji, ale z reguły wymagają one ogromnej liczby obliczeń, niewykonalnych nawet na najszybszych współczesnych komputerach. Tymczasem w 1975 roku John Hery Holland wymyślił, że najlepsze rozwiązanie takich złożonych problemów najlepiej jest po prostu… wyhodować.
Pomysł Hollanda był następujący: jeśli dla rozwiązania problemu potrzebne jest podjęcie szeregu decyzji, to zbudujmy łańcuch „okienek”, w których można zapisywać, jaką decyzję na jakiś temat byśmy podjęli, gdyby nam na to pozwolono. Takich decyzji cząstkowych trzeba podjąć całe mnóstwo, więc łańcuch okienek będzie bardzo długi. W każdym okienku można wpisać 1, jeśli przypisana do tego okienka decyzja jest pozytywna, albo 0, gdy owa decyzja jest negatywna.
Hollandowi taki łańcuch zer i jedynek kojarzył się z chromosomem, to znaczy łańcuchem cząsteczek DNA zapisującym w naszych genach wszystkie cechy naszego organizmu. Mając chromosom, mamy de facto „osobnika”, którego działanie może przynosić określony skutek.
Uroda podejścia Hollanda polegała na tym, że nie rozważał on tylko pojedynczego osobnika, tylko całą ich populację. Pierwsza taka populacja powstawała w ten sposób, że chromosomy pewnej liczby „osobników” były tworzone losowo. Do poszczególnych okienek chromosomu jednego osobnika wstawiano zera i jedynki wybierane w sposób losowy. Komputer ma taką możliwość, że na życzenie może obliczać wartości przypadkowe.

Przykładowe krzyżowanie chromosomów zakodowanych binarnie w algorytmach genetycznych. Źródło: Wikipedia
Po wypełnieniu jednego łańcucha okienek owymi przypadkowo generowanymi jedynkami i zerami – czyli po wykreowaniu chromosomu jednego „osobnika” – w podobny sposób generuje się chromosom drugiego, potem trzeciego, czwartego i piątego „osobnika”, aż do zapewnienia takiej liczby osobników, jaką użytkownik algorytmu genetycznego, traktowanego jako wykorzystywane narzędzie sztucznej inteligencji, uzna za stosowne.
I tu zaczyna się najciekawsze! Osobniki konkurują ze sobą, bo każdy chce wydać „potomstwo”, które wejdzie w skład następnego pokolenia. Jak dochodzi do „spłodzenia” takiego potomka, o tym napiszę innym razem, ale zapewniam, że ten seks w komputerze bywa bardzo gorący!
Ponieważ każda wylosowana para „rodziców” generuje dwoje potomków, więc po wykonaniu odpowiedniej liczby tych aktów prokreacji mamy skompletowaną tak samo liczną populację potomków. Osobniki z poprzedniej populacji są wtedy usuwane, a dalsze działania dotyczą tylko owej populacji potomków. Każdy z nich jest oceniany i znowu znajdujemy tych najlepszych „osobników”, których dopuszczamy do rozmnażania wraz z procesem losowego mieszania fragmentów chromosomów i znowu dokonujemy wymiany pokoleń. Aż wreszcie najlepszy osobnik którejś kolejnej generacji daje potrzebne rozwiązanie! W ten sposób sztuczna inteligencja może „wyhodować” najlepszy sposób postępowania i zapewnić maksymalny zysk!
Głębokie uczenie i rozwiązywanie problemów
Kolejnym „kamieniem milowym” w moim opisie rozwoju sztucznej inteligencji jest głębokie uczenie. Sieci neuronowe opisane wyżej najczęściej składały się z trzech (maksymalnie) warstw neuronów, których połączenia – tak zwane wagi synaptyczne – podlegały procesowi uczenia. Zasadniczy postęp w 1995 roku osiągnęli Terrence Sejnowski, Peter Dayan i Geoffrey Hinton. Owi badacze wymyślili metodę uczenia sieci neuronowej o bardzo wielu warstwach, którą nazwano „głębokim uczeniem”.
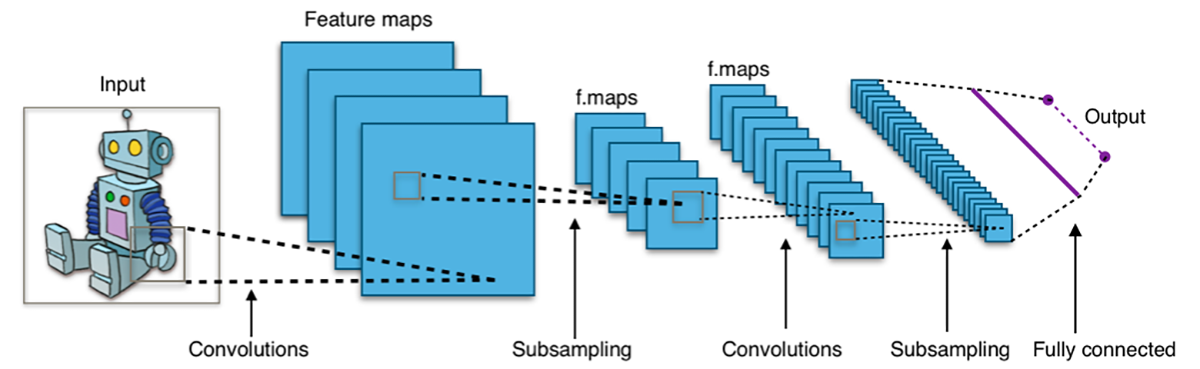
Typowa architektura CNN. Źródło: Wikipedia
Najczęstsza forma realizacji tych sieci opierała się na wykorzystywaniu warstw konwolucyjnych, stąd sieci te określane były skrótową nazwą CNN od określenia Convolutional Neural Network. W krótkim czasie ukazało się mnóstwo prac naukowych potwierdzających skuteczność CNN w rozwiązywaniu różnych problemów.

Pracownicy grupy badań nad głębokim uczeniem w 2016 roku. Od lewej do prawej: Ruslan „Russ” Salakhutdinov, Richard S. Sutton, Geoffrey Hinton, Yoshua Bengio i Steve Jurvetson. Źródło: Wikipedia
Potem przyszła praktyka. Wpływ głębokiego uczenia (ang. deep learning) w przemyśle rozpoczął się na początku lat dwutysięcznych, kiedy CNN przetwarzały już szacunkowo 10% do 20% wszystkich czeków wystawionych w USA. W październiku 2012 r. sieć o nazwie AlexNet, autorstwa doktorantów Uniwersytetu w Toronto, Alexa Krizhevsky’ego, Ilyi Sutskevera i ich promotora Geoffreya Hintona wygrała zakrojony na szeroką skalę konkurs ImageNet ze znaczną przewagą nad wszystkimi innymi metodami uczenia maszynowego. Ten fakt przekonał niedowiarków i na długi czas głębokie sieci konwolucyjne oraz metody ich głębokiego uczenia stały się najważniejszym nurtem w historii sztucznej inteligencji. Właściwie okres ich dominacji nadal trwa.
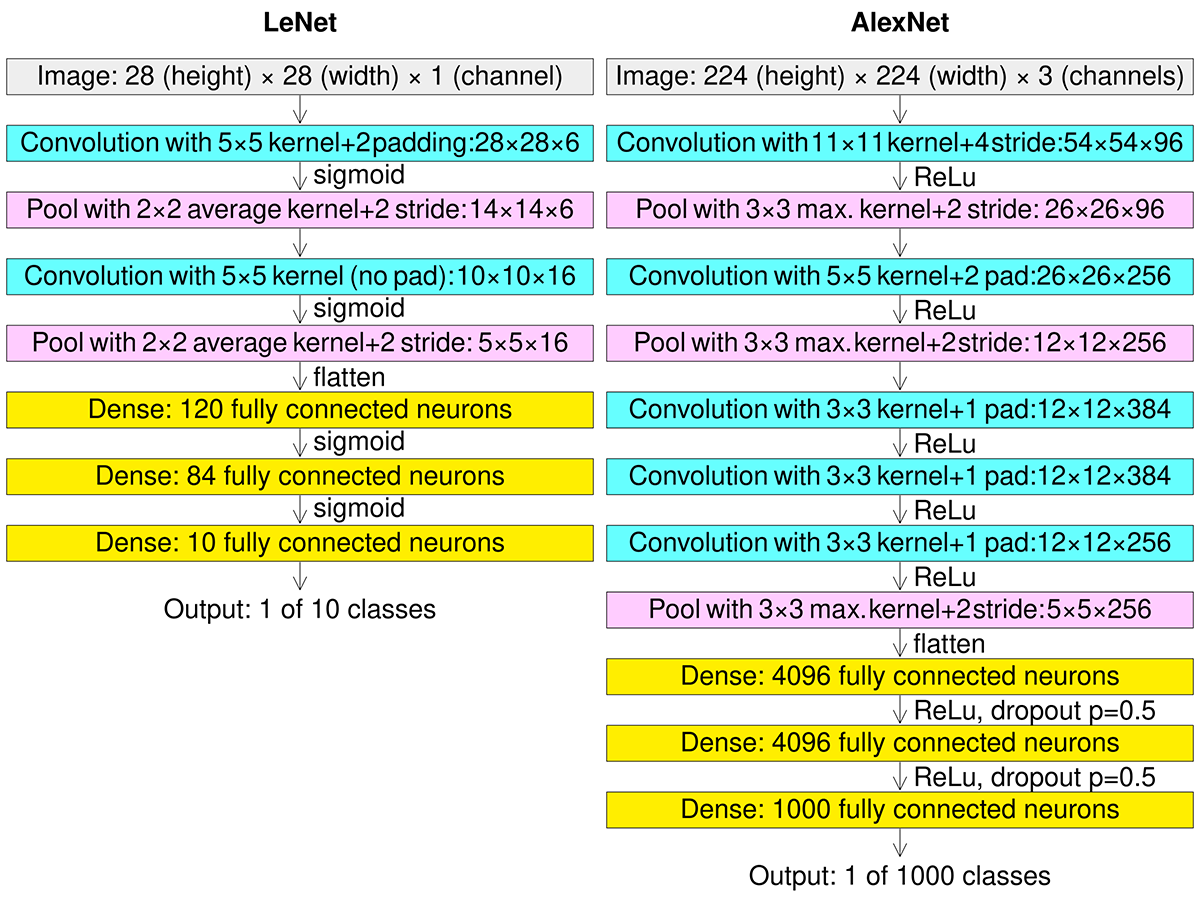
Porównanie architektur CNN LeNet i AlexNet z warstwą wejściową (kolor szary) i konwolucyjną (kolor niebieski), łączenia (kolor różowy) i połączeń każdy-z-każdym (kolor żółty). Źródło: Wikipedia
Zbiory rozmyte i logika rozmyta – w mniejszym lub większym stopniu
Następny „kamień milowy” na wytyczonej przeze mnie drodze rozwoju sztucznej inteligencji ma nazwę zbiory rozmyte i logika rozmyta. Pojęcie rozmytości polega na tym, że zamiast kategorycznego podziału według schematu „tak – nie” wprowadza się pojęcie, że coś jest jakieś w pewnym stopniu. Stopień ten może wynosić 100% i wtedy jest równoważny klasycznemu „tak” albo może wynosić 0% i wtedy jest równoważny klasycznemu „nie”. Jednak ciekawe i oryginalne są sytuacje, gdy coś jest jakieś w stopniu pomiędzy 0% a 100%. Trochę mętne sformułowania przytoczone powyżej wynikają z faktu, że rozmytość może dotyczyć różnych rzeczy. W historii sztucznej inteligencji jako pierwsza zapisała się książka „Fuzzy Sets” (Zbiory rozmyte) opublikowana w 1966 roku przez Lotfi Zadeha. W książce tej Zadeh wykazał, że obok klasycznych zbiorów, w których elementy albo w pełni należą do zbioru, albo zdecydowanie do niego nie należą (takie zbiory nazywa się czasem zbiorami Cantora), mogą istnieć zbiory, w których elementy będą należeć do zbioru tylko w pewnym stopniu.
Na przykład zbiorem klasycznym jest zbiór czytelników tego artykułu. Albo ktoś go w danym momencie czyta, albo nie czyta. Natomiast zbiorem rozmytym będzie zbiór osób zainteresowanych historią sztucznej inteligencji. Są tacy, których to wcale nie interesuje, są tacy, których to interesuje maksymalnie, ale są też tacy, których to interesuje w pewnym stopniu. Mniejszym lub większym – ale właśnie takim pośrednim. O tym, jak bardzo konkretny obiekt należy do rozważanego zbioru, decyduje funkcja przynależności. Jeśli o przynależności decyduje jakiś dający się wyrazić ilościowo czynnik, to funkcję przynależności można narysować jako wykres – najczęściej zbudowany z linii o określonym nachyleniu, pokazujących w jakim stopniu obiekt o określonej wartości do rozważanego zbioru rozmytego należy.
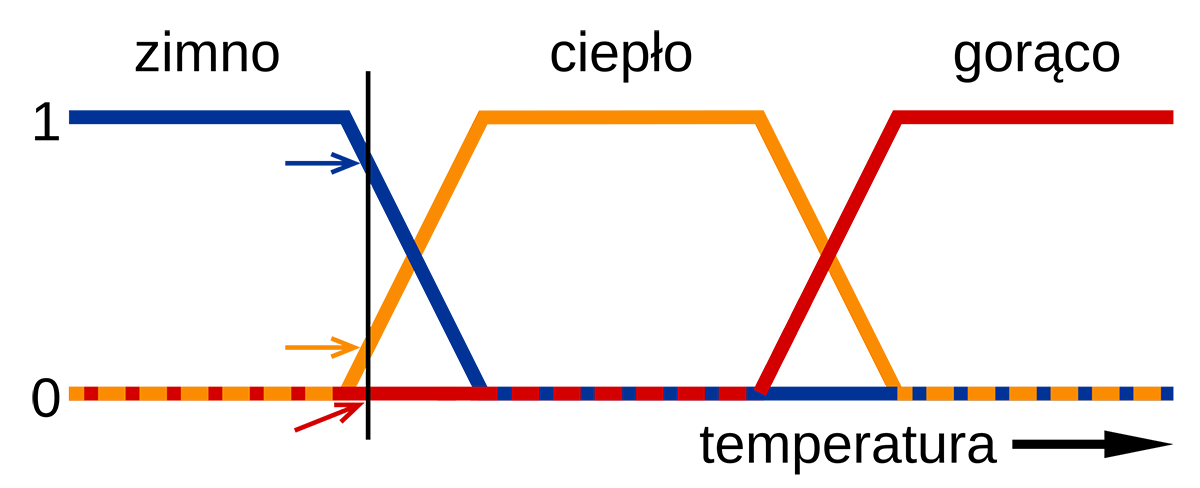
Zaznaczonej czarną pionową linią temperaturze można przypisać jednocześnie wartości, które można zinterpretować jako: dość zimna, ledwo ciepła i jeszcze nie gorąca. Takie podejście pozwala przykładowo na regulację działania układów hamulcowych.
Wiele ciekawych przykładów zbiorów rozmytych można zbudować na bazie parametru, jakim jest czas. Powiedzmy, że chcemy zdefiniować zbiór pod nazwą „młodzież”. Nie ulega wątpliwości, że ludzie w pewnym przedziale wiekowym (na przykład moi studenci) do tego zbioru z całą pewnością należą. Tu wartość funkcji przynależności wynosi 100%. Są też tacy ludzie, których do tego zbioru zaliczyć zdecydowanie nie można – na przykład ja sam już zdecydowanie do tego zbioru nie należę (funkcja przynależności 0%). Do zbioru „młodzież” także nie należy moja siedmioletnia wnuczka.
Jednak przejście między kategorią „młodzież”, a kategorią „seniorzy” nie może mieć charakteru ostrego, binarnego. Nie do pomyślenia jest sytuacja, w której wyznaczony byłby rok, miesiąc i dzień życia, do którego się należy do zbioru „młodzież”, a potem nadchodzi chwila (może wyznaczona z dokładnością do godziny, minuty i sekundy?) i się już do „młodzieży” przestaje należeć. Podobny paradoks wiązałby się z dokładnym wyznaczeniem momentu życia, w którym dziecko przestaje być dzieckiem i musi być zaliczane do kategorii młodzieży. Konieczne jest więc zbudowanie zbioru rozmytego, który by przypisywał wiekowi moich studentów stuprocentową przynależność do zbioru „młodzież”, mnie oraz mojej wnuczce 0% przynależności – ale niezbędne jest też poprowadzenie linii wznoszącej do 0 do 100 procent po stronie przechodzenia z kategorii „dziecko” do kategorii „młodzież” oraz linii opadającej od 100% do zera po stronie wkraczania w wiek senioralny. Odpowiada to nawet potocznym rozumowaniom w formie zachwytu: „Ależ to dziecko ślicznie się rozwija, wkrótce to będzie dzielny młodzieniec” albo stwierdzeniu: „No taki młody to on już nie jest – chyba trzeba się szykować na emeryturę”.
Po zbiorach rozmytych została opracowana logika rozmyta, w której pomiędzy pojęciem całkowitego fałszu (zwykle symbolizowanego przez 0) a całkowitej prawdy (oznaczanej zwykle jako 1) możliwe są stany pośrednie („możliwy fałsz”, „przypuszczalnie prawda” itp.). Nie mam tu jednak miejsca, żeby ten wątek rozwijać.
Sztuczna inteligencja wygrywa z człowiekiem
Ostatnim wyróżnionym przeze mnie „kamieniem milowym” rozwoju sztucznej inteligencji są programy wygrywające z ludźmi. Sztuczna inteligencja odnotowała już bardzo wiele sukcesów, zaspokajając ważne potrzeby, między innymi w obszarach wyszukiwania potrzebnych informacji, biznesu i finansów, medycynie i ochronie zdrowotnej, transporcie i logistyce – można by długo wyliczać. Ale najwięcej emocji wywołują informacje, że sztuczna inteligencja grała z człowiekiem i pokonała go. Kiedyś opiszę historię zmagań ludzi z programami komputerowymi grającymi w szachy, bo ta historia jest pełna zaskakujących i zabawnych wydarzeń. Natomiast wspomnę o tym, jaki był finał owego wyścigu intelektu ludzkiego i sztucznej inteligencji.
Największa sensacja wydarzyła się w 1997 roku, kiedy to system Deep Blue pokonał arcymistrza szachowego. Najpierw przedstawmy owego człowieka. Garry Kimowicz Kasparow, bo tak się on nazywał, był mistrzem świata w szachach i bezwzględnym arcymistrzem. Uzyskał ten tytuł w wieku 22 lat, pokonując w 1985 roku ówczesnego arcymistrza Anatolija Karpowa. Karpow nie mógł uwierzyć, że został pokonany (wcześniej odnosił same sukcesy), więc starł się Kasparowem jeszcze trzykrotnie, w latach 1986, 1987 i 1990. Za każdym razem przegrał. W 1993 roku Międzynarodowa Federacja Szachowa FIDE przyznała Kasparowowi bezwzględny tytuł mistrza świata.
Piszę o tym tak obszernie, bo chciałbym rozprawić się z pewnym krzywdzącym dla sztucznej inteligencji poglądem lansowanym przez niektórych krytyków. Otóż ci krytycy powiadają, że to nie komputer posługujący się sztuczną inteligencją pokonał Kasparowa („wymyślając” na bieżąco, co i jak trzeba zrobić, żeby go pokonać), tylko ktoś bardzo mądry tak go zaprogramował, żeby wygrał.

Arcymistrza szachowy Garri Kimowicz Kasparow, a obok Deep Blue – komputer grający w szachy, stworzony przez IBM. Źródło: Wikipedia
Otóż w momencie toczenia meczu Kasparow kontra Deep Blue nie było na świecie człowieka, który by wygrał z Kasparowem. Pokonywał wszystkich! Nie było więc także możliwe, by ktoś zaprogramował, co komputer ma robić, żeby wygrać. Takiego mądrego nie było. A komputer wygrał!
O ile sprawa sztucznej inteligencji w obszarze rozgrywek szachów została w ten sposób zamknięta, o tyle pojawiło się nowe wyzwanie: dalekowschodnia gra w Go. Tysiące razy bardziej skomplikowana od szachów!
A jednak w 2014 roku zadanie zbudowania programu wygrywającego z człowiekiem w Go podjęła grupa badawcza określona jako Deep Mind. Jej nazwa brała się stąd, że jako główne narzędzie wykorzystywała głębokie sieci neuronowe, opisane wyżej. Program stworzony przez tych badaczy nazywał się AlphaGo. W październiku 2015 roku pokonał on mistrza Europy w grze w Go o nazwisku Fan Hui.

Goban (plansza do gry w go) z kamieniami zagranymi w czasie gry. Źródło: Wikipedia
Na drodze do ostatecznego sukcesu był już tylko jeden przeciwnik: nieformalny mistrz świata w Go, Lee Sedol. Specjaliści oceniają, że był on najsilniejszym graczem w historii gry w Go. Sukcesy odnosił od 12 roku życia, 18 razy zdobył różne najwyższe tytuły mistrzowskie w Go, kilka tygodni przed konfrontacją z programem AlphaGo zdobył koreański tytuł Myungin, czyli mistrza nad mistrzami.
Mecz „o wszystko” miał miejsce w Seulu i trwał od 9 do 15 marca 2016 roku. Z pięciu meczów program AlphaGo wygrał cztery. Była to światowa sensacja. Oto padł ostatni bastion przewagi człowieka nad sztuczną inteligencją! Czasopismo Science 22 grudnia 2016 określiło ten wynik jako „Przełom roku”.
„Krótka historia sztucznej inteligencji”
Zaprezentowany artykuł przedstawił tylko zarys niektórych wydarzeń związanych z historią sztucznej inteligencji. Ale – jak już wspomniałem na wstępie – na początku 2026 roku wydawnictwo warszawskie o nazwie RM wyda moją książkę, zatytułowaną „Krótka historia sztucznej inteligencji”. Wprawdzie w tytule jest zapowiedziana, że historia będzie krótka, ale wydanie będzie miało około 500 stronic objętości. Jeśli więc kogoś ten artykuł zainteresował, to zapraszam do sięgnięcia po ową niedługo dostępną książkę. Tam naprawdę będzie dużo informacji!
 „Pierwsze osiągnięcie sztucznej inteligencji było oszustwem” – prof. Ryszard Tadeusiewicz
„Pierwsze osiągnięcie sztucznej inteligencji było oszustwem” – prof. Ryszard Tadeusiewicz  Świat w jakim żyjemy został w dużej mierze ulepszony dzięki elektronice. Co jednak wiemy o ludziach, którzy tego dokonali? – felieton prof. Ryszarda Tadeusiewicza
Świat w jakim żyjemy został w dużej mierze ulepszony dzięki elektronice. Co jednak wiemy o ludziach, którzy tego dokonali? – felieton prof. Ryszarda Tadeusiewicza  Twórca koncepcji sztucznej inteligencji został wykastrowany, ale intelektualnie zapłodnił setki naśladowców
Twórca koncepcji sztucznej inteligencji został wykastrowany, ale intelektualnie zapłodnił setki naśladowców 






