





Prof. Ryszard Tadeusiewicz: Sztuczna inteligencja wykorzystująca seks w komputerze
Metody wykorzystywane w sztucznej inteligencji mogą polegać na stworzeniu odpowiedniego do potrzeb algorytmu (tak działają szeroko stosowane metody symboliczne), mogą opierać się na uczeniu (rozpoznawanie obrazów, sieci neuronowe, uczenie głębokie) ale mogą także korzystać z tego, że potrzebne rozwiązanie można sobie wyhodować. Wystarczy zdefiniować osobnika rozwiązującego (lepiej lub gorzej) rozważany problem, potem wytworzyć całe pokolenie takich osobników i zamodelować proces sztucznej ewolucji w której wygrywają te osobniki które najlepiej rozwiązują postawione zadanie. Tak to wymyślił jako pierwszy John Henry Holland (w 1975), a potem tą drogą poszli liczni następcy, rozwinięto dział sztucznej inteligencji nazywany „Algorytmami genetycznymi”.

Prof. dr hab. inż. Ryszard Tadeusiewicz | źródło ilustracji po prawej stronie: Freepik
Zacznijmy od scharakteryzowania sytuacji i okoliczności, w których to podejście jest użyteczne
Wyobraźmy sobie, że konieczne jest wybranie jakiegoś rozwiązania w sytuacji, gdy owo rozwiązanie składa się z bardzo wielu decyzji dotyczących różnych spraw, składających się łącznie na jakąś strategię działania. Przykładowo mamy pewien teren do zagospodarowania i chcemy, żeby przyciągnął on wielu zamożnych inwestorów, którzy zapewnią podatki dla gminy i dadzą zatrudnienie okolicznej ludności. Ale inwestorzy mają swoje wymagania, więc gmina musi najpierw zdecydować, gdzie trzeba przeprowadzić drogi, jak rozwiązać problem zaopatrzenia w energię i wodę, jak zorganizować sieć łączności, gdzie przewidzieć możliwość budowy magazynów, a gdzie zakładów wytwórczych itp. Oczywiście takich częściowych decyzji trzeba podjąć setki i nikt tego całościowo nie ogarnie.
W związku z tym budujemy listę tych decyzji (poszczególnych cech poszukiwanego rozwiązania), które trzeba podjąć, schodząc do poziomu tak prostych rozstrzygnięć, że mogą być one wyrażone w postaci decyzji TAK albo NIE. Zapisując te cząstkowe decyzje w postaci „1” (pozytywna) lub „0” (negatywna) otrzymujemy wektor binarny. Zwykle bardzo długi!
Ten wektor nazwiemy „chromosomem” (nawiązując do terminologii używanej w genetyce), a po zapełnieniu go konkretnymi wartościami zer i jedynek na poszczególnych pozycjach taki „chromosom” nazywać będziemy „osobnikiem”.
Spójrzmy na rysunek 1. Mamy na nim porównane pojęcia „osobnika” w biologii i w omawianej tu technice sztucznej inteligencji nazywanej algorytmem genetycznym. Analogia jest mocno naciągana, ale okazała się zaskakująco skuteczne i z jej pomocą rozwiązano bardzo wiele trudnych problemów decyzyjnych. Omówię teraz, jak to osiągnięto, ostrzegając purystycznych Czytelników, że będzie między innymi o seksie w komputerze, więc może lepiej dalej nie czytać?
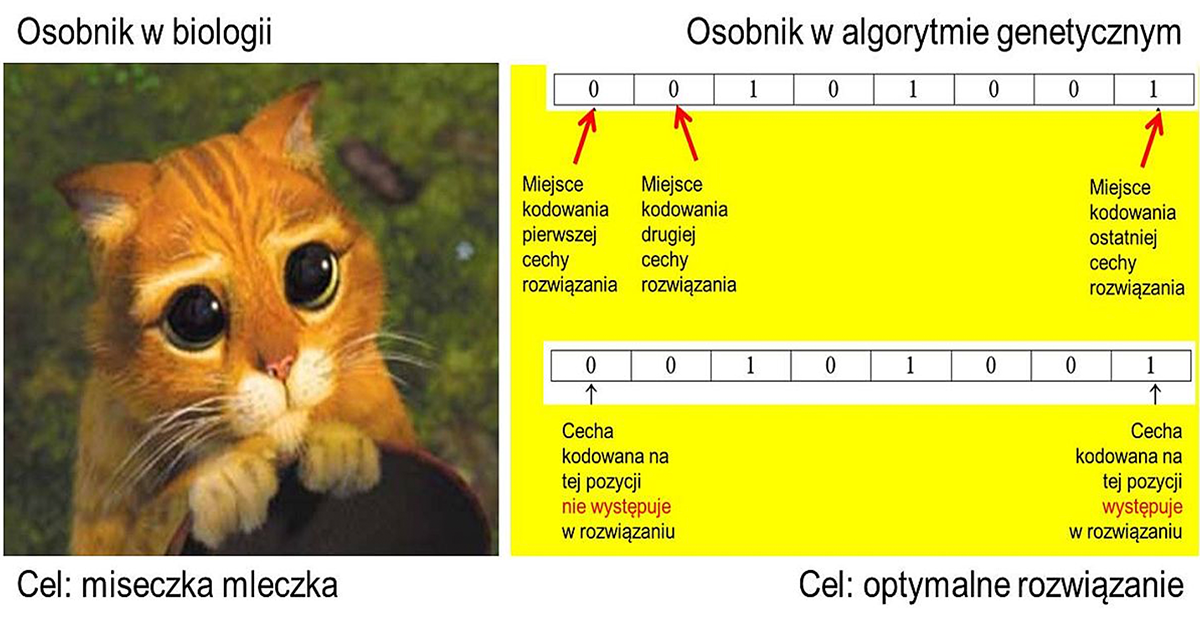
Rys. 1. Porównanie podstawowych pojęć w biologii i w algorytmie genetycznym należącym do sztucznej inteligencji
Z tymi, którzy postanowili wytrwać, kontynuuję opis działania algorytmu genetycznego
Zacząć trzeba od wykreowania „osobnika”. Od tej chwili słowo to będzie rozumiane jako równoważnik wypełnionego konkretnymi wartościami (0 i 1) „chromosomu”. Dla prostoty słowa osobnik i chromosom będą pisane bez cudzysłowu, chociaż ze świadomością, że chodzi o elementy w algorytmie genetycznym, a nie ich biologiczne pierwowzory.
Pierwsze osobniki tworzone są przez losowe wypełnianie chromosomów zerami i jedynkami. Takich osobników generujemy w pewnej arbitralnie wybranej liczebności tworząc w ten sposób pierwszą populację. Potem każdego osobnika oceniamy w ten sposób, że symulujemy w rozważanym problemie decyzyjnym takie właśnie decyzje, jakie wynikają z zer i jedynek w chromosomie tego osobnika. Symulacja pozwala stwierdzić, jaki byłby całkowity zysk osiągnięty przy decyzjach opartych na zawartości chromosomu tego osobnika.
Gdy ocenimy każdego osobnika z rozważanej pierwszej (losowej!) populacji – okaże się, że jedni poradzili sobie lepiej, a drudzy gorzej. Na ogół zresztą te wyniki dla osobników pierwszej populacji są wszystkie mizerne (no bo mała jest szansa, by decyzje podejmowane de facto losowo przyniosły jakiś sensowny sukces), ale da się każdemu osobnikowi przypisać jakąś miarę jakości decyzji wynikających z jego chromosomu.
I teraz zaczyna się ten seks w komputerze!
Osobników łączymy w pary i pozwalamy im spłodzić potomków. O tym, czy dany konkretny osobnik będzie dopuszczony do tej prokreacji decyduje miara jakości decyzji opartych na jego chromosomie. Im większy sukces odniósł osobnik – tym większa jest szansa by został on wylosowany (za pomocą mechanizmu podobnego do ruletki) aby być „rodzicem” potomka, który przejdzie do następnej populacji. Ten mechanizm promuje tych „najzdolniejszych” osobników, ale nie wyklucza definitywnie tych, którzy mieli bardzo marne sukcesy, bo może się zdarzyć, że potomek takiego nieudacznika w następnej populacji okaże się liderem. Nasuwa się tu żartobliwa analogia z tym, że kiedyś w pra-dżungli żyły sobie małpy, które się dobierały tak, że samiec, który najzręczniej wspinał się po gałęziach mógł zapłodnić największą liczbę samic. Wydawało się, że potomstwo takich samców zawładnie dżunglą. A tymczasem była taka małpa, która marnie chodziła po drzewach, zeszła więc na ziemię, chodziła tylko na dwóch łapach, używając górnych kończyn do wykonywania różnych czynności – i potomstwo tej właśnie nieudanej małpy decyduje teraz o tym, czy cała dżungla ma prawo istnieć, czy nie.
Powracając od tego żartu do opisu algorytmu genetycznego stwierdzamy, że dwa losowo (ale w sposób zależny od osiągniętych sukcesów!) wybrane osobniki mają spłodzić potomków (także dwóch), którzy wejdą w skład następnej populacji. Odbywa się to w taki sposób, że chromosomy obu osobników są zestawiane, a potem przecinanie w losowo wybranym punkcie i wymieniane – jeden osobnik potomny ma pierwszą część chromosomu „matki” i drugą część „ojca” – a drugi odwrotnie (Rys.2).
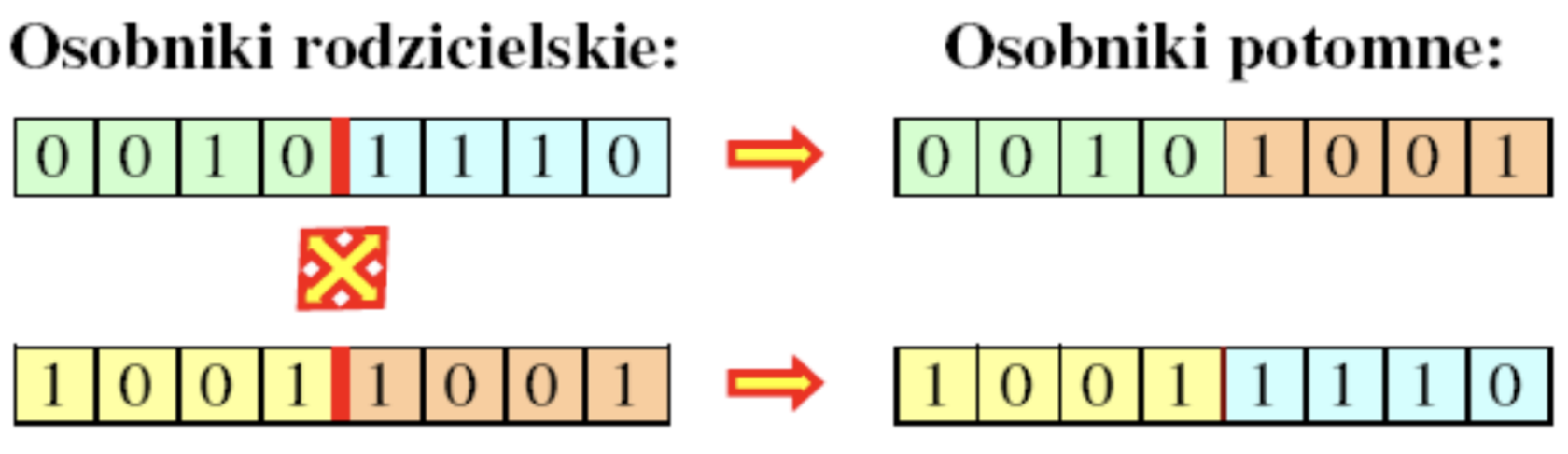
Rys. 2. Wymiana „informacji genetycznej” podczas płodzenia potomków
Dlaczego ten mechanizm może generować osobników potomnych osiągających większe sukcesy niż osobniki rodzicielskie? Popatrzymy na rysunek 3. Niech wizerunek tarczy strzelniczej symbolizuje poziom sukcesu odnoszonego przez osobników. Niech czerwone punkty oznaczają osobników rodzicielskich – każdy z nich odniósł sukces (dzięki temu został rodzicem), ale niepełny. Natomiast ich potomek (oznaczony żółtym trójkątem) może znaleźć się bliżej pełnego sukcesu.
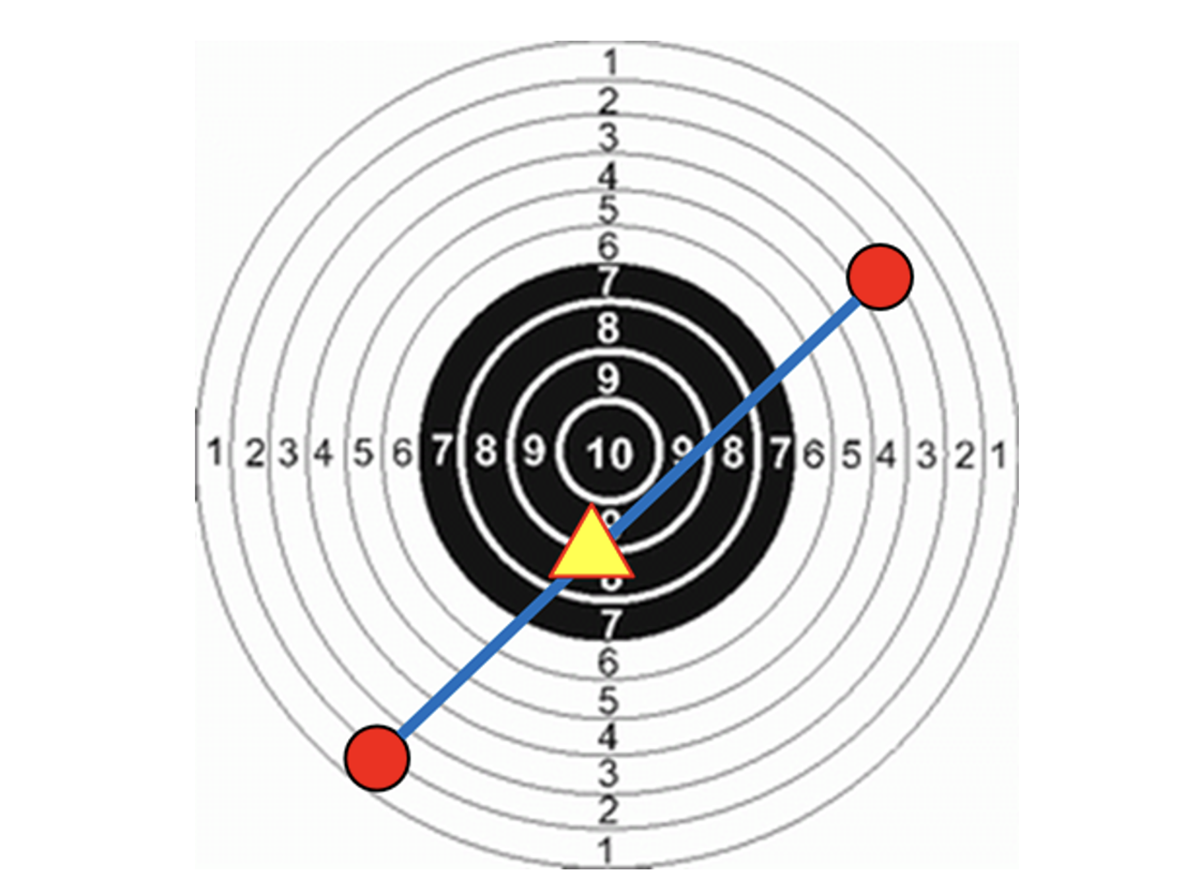
Rys. 3. Powód, dla którego potomek może osiągnąć lepszy wynik, niż rodzice
W biologii czynnikiem napędowym ewolucji jest także stosowanie mutacji. Oznacza ona losową zmianę jednego z elementów chromosomu. W biologii występuje ona rzadko i w algorytmach genetycznych także nadmiernie się nią nie szarżuje, ale mutacja może być sposobem na uwolnienie się od błędnej tendencji, która dotknęła całą populację osobników. Ilustruje to rysunek 4.
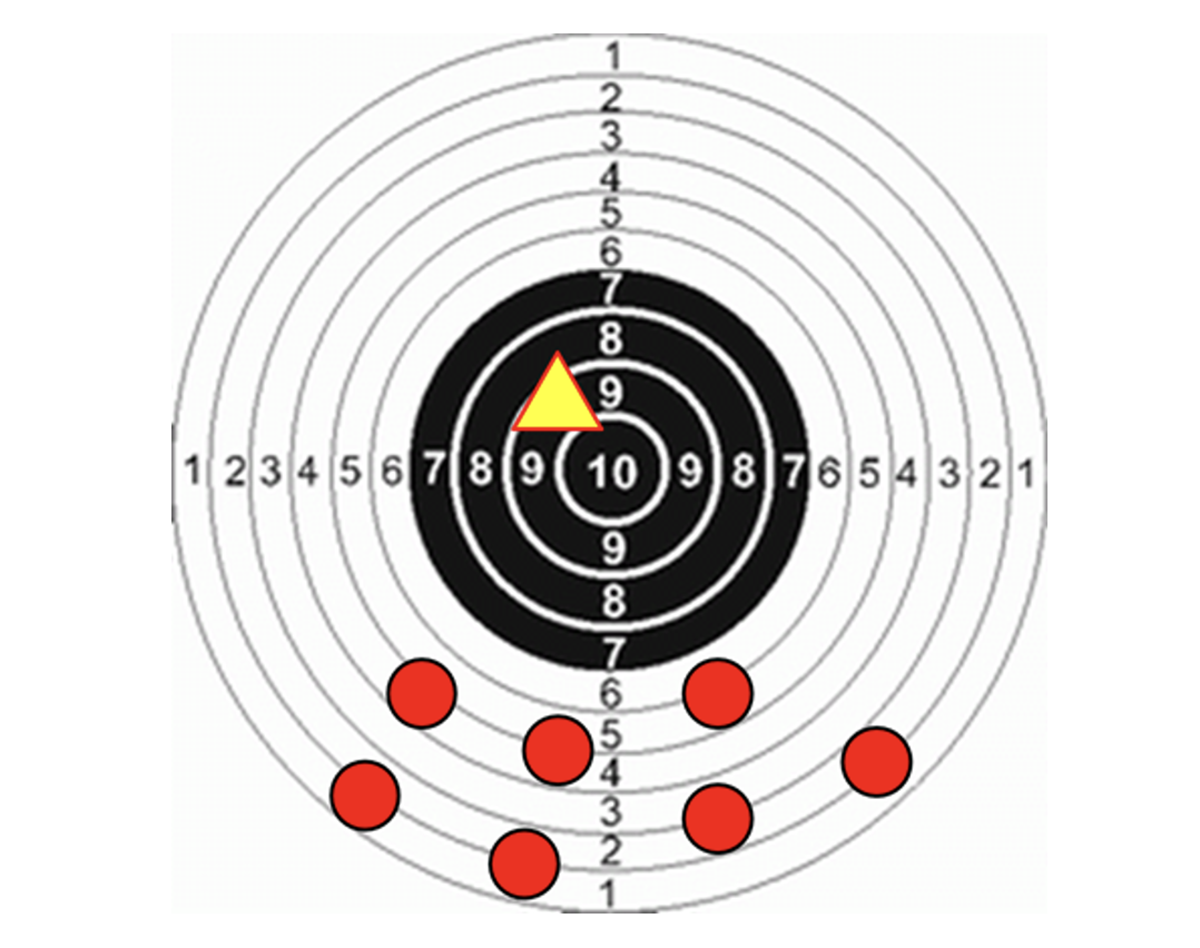
Rys. 4. Rola mutacji
Po wykonaniu takiej liczby czynności płodzenia potomków, by uzyskać populację o takiej samej liczebności, jak populacja pierwotna – następuje wymiana pokoleń. Poprzednie osobniki zostają usunięte i rywalizacja o możliwie najlepszy wynik problemu decyzyjnego przebiega w kolejnym pokoleniu osobników. I tak pokolenie za pokoleniem powstają osobniki, które coraz lepiej rozwiązują postawione zadanie. Pokazane jest to na rysunku 5. Kółka oznaczają osobników. Na osi poziomej odkładane są kolejne numery populacji, a na osi pionowej – jakość rozwiązania postawionego zadania. Poszczególne pary rodzicielskie w kolejnych pokoleniach wydają kolejnych potomków, aż wreszcie „rodzi się” potomek rozwiązujący postawione zadanie wystarczająco dobrze.
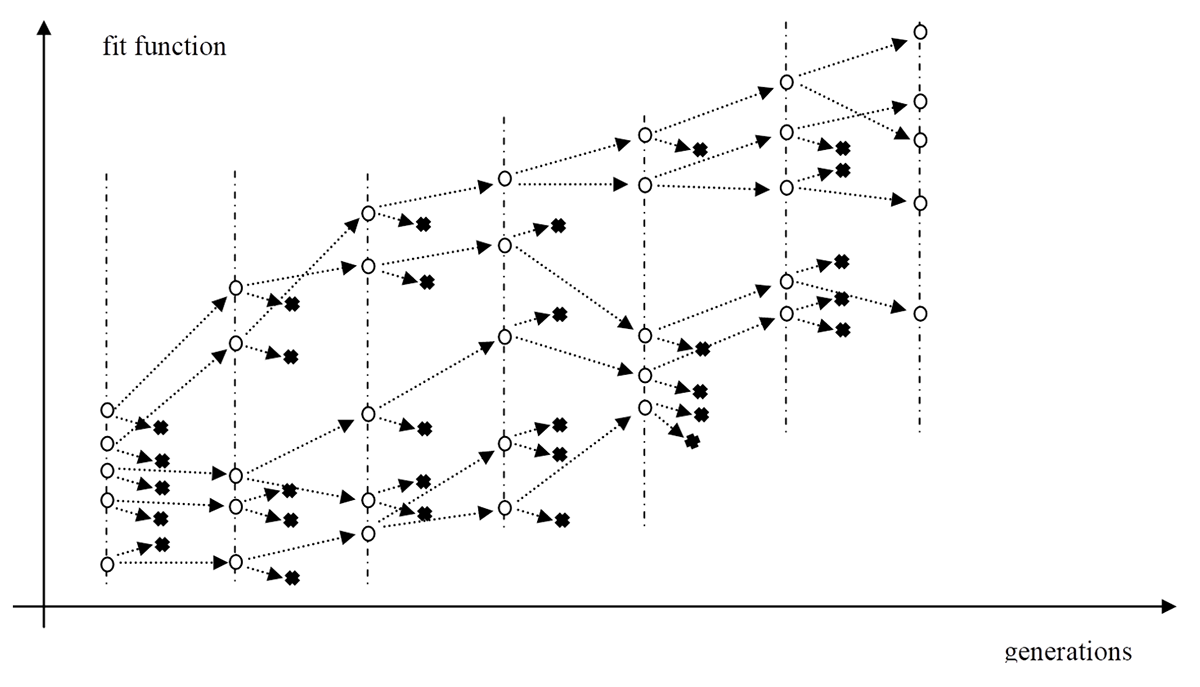
Rys. 5. Przebieg ewolucji w algorytmie genetycznym
Pracę algorytmu genetycznego przerywa się, gdy uzyskane rozwiązanie jest już wystarczająco dobre. Nigdy nie ma gwarancji, że będzie to rozwiązanie optymalne, to znaczy najlepsze możliwe. A jeśli jest zadowalające – to możemy uznać, że osiągnęliśmy sukces.
Niestety w algorytm genetyczny trzeba zawsze wstawić także „hamulec bezpieczeństwa”. Może się zdarzyć – jak przy każdym procesie obliczeniowym z dużą liczną elementów losowych – że kolejne pokolenia wcale nie będę coraz lepsze, a proces ich generacji i sprawdzania będzie trwał w nieskończoność. Dlatego trzeba się zawsze na początku umówić: Testujemy najwyżej sto (przykładowo) generacji. Albo wcześniej znajdziemy osobnika wystarczająco dobrego – albo rezygnujmy.
Niestety, sztuczna inteligencja musi zawsze przewidywać także możliwość porażki…
 Prof. Ryszard Tadeusiewicz: Dlaczego w historii początków elektrotechniki i elektroniki jest tak niewiele polskich nazwisk?
Prof. Ryszard Tadeusiewicz: Dlaczego w historii początków elektrotechniki i elektroniki jest tak niewiele polskich nazwisk?  Kamienie milowe rozwoju sztucznej inteligencji – według prof. Ryszarda Tadeusiewicza
Kamienie milowe rozwoju sztucznej inteligencji – według prof. Ryszarda Tadeusiewicza  „Pierwsze osiągnięcie sztucznej inteligencji było oszustwem” – prof. Ryszard Tadeusiewicz
„Pierwsze osiągnięcie sztucznej inteligencji było oszustwem” – prof. Ryszard Tadeusiewicz 

![O konkursie organizowanym przez firmę TRUMPF Huettinger i polskie uczelnie techniczne opowiada Alicja Peresada i prof. Jacek Rąbkowski oraz kilkoro nagrodzonych dyplomantów: mgr inż. Jakub Dobosz, inż. Maja Zielińska, dr inż. Jakub Kołodziej, dr inż Weronika Hryniewska-Guzik i dr inż. Grzegorz Bartyzel. Zapraszamy do obejrzenia filmu! [materiał redakcyjny]](https://mikrokontroler.pl/wp-content/uploads/2026/07/TRUMPF-czolowka.png "https://www.youtube.com/watch?v=XkeyLmtLfxo")



