





Możliwości realizacji sztucznej inteligencji w systemach wbudowanych
Sztuczną Inteligencję (AI – Artificial Intelligence) uważa się za technologię niezbędną do rozwoju Internetu Rzeczy (IoT – Internet of Things) i cyber–fizycznych systemów, takich jak roboty i autonomiczne pojazdy. Inteligentny głośnik, jaki stoi teraz w salonach w wielu domach, to dobry przykład zaawansowanej sztucznej inteligencji w akcji, działającej w codziennym życiu. Taki głośnik jest w stanie rozpoznawać wypowiadane zdania oraz syntezować wysokiej jakości mowę. By realizować te funkcje, głośnik musi przekazywać dane do wielu bardzo szybkich komputerów, ulokowanych w odległych serwerowniach. Sprzęt wbudowany uważa się za zbyt ograniczony, by być w stanie obsługiwać takie rodzaje głębokich sieci neuronowych (DNN – Deep Neural Network), na jakich polegają wykorzystywane algorytmy.

Zastosowania Sztucznej Inteligencji
Sztuczna Inteligencja wcale nie musi być ograniczona do implementacji na wysoce-wydajnych maszynach, zlokalizowanych w wielkich serwerowniach. Technologie AI są obecnie proponowane jako sposób na zarządzanie niezmiernie skomplikowanym protokołem radiowym sieci 5G. Liczba parametrów które muszą być przeanalizowane przez telefony przewyższyła już możliwości inżynierów w zakresie tworzenia efektywnych algorytmów. Algorytmy trenowane na danych, uzyskanych w trakcie testów polowych, pozwalają sprawniej równoważyć poszczególne czynniki w trakcie transmisji i lepiej dobierać jej ustawienia.
Podobnie w dziedzinie utrzymywania sprawności sprzętu przemysłowego, pracującego w zdalnych lokalizacjach, algorytmy uczenia maszynowego na systemach wbudowanych stają się efektywnym rozwiązaniem. Tradycyjne algorytmy, takie jak np. oparte o filtry Kalmana, dobrze radzą sobie z liniowymi zależnościami pomiędzy różnymi danymi wejściowymi – np. informacjami o ciśnieniu, temperaturze i wibracjach. Ale wczesne wykrywanie zbliżających się problemów często wymaga wykrywania wysoce nieliniowych zmian pomiędzy zależnościami wśród tych danych.
Implementacja Sztucznej Inteligencji
Systemy sztucznej inteligencji można szkolić na danych pochodzących ze zdrowych maszyn oraz z maszyn, w których pojawiają się usterki. Dzięki temu później są w stanie wykrywać potencjalne problemy, gdy w czasie rzeczywistym będą nadchodziły nowe dane. Jednakże, sieć neuronowa, jakkolwiek jest obecnie popularnym wyborem, nie jest jedynym dostępnym rozwiązaniem, zaliczanym do sztucznej inteligencji. Jest wiele algorytmów, które można zastosować i czasem to jedna z alternatyw najlepiej nadaje się do użycia w danym zadaniu.
Jednym z takich rozwiązań jest sztuczna inteligencja oparta na zasadach (Rule-Based AI). Bazuje ona na wiedzy eksperckiej, zamiast na bezpośrednim uczeniu maszynowym, a to za sprawą wprowadzonych informacji tworzącej bazę zasad.
System następnie analizuje dane pod kątem zgodności z poszczególnymi zasadami i stara się znaleźć najlepsze dopasowanie do warunków, na jakie natrafia. Systemy tego typu cechują się niską złożonością obliczeniową, ale często sprawiają problemy dla programistów. Szczególnie wtedy, gdy podane warunki są trudne do wyrażenia za pomocą prostych stwierdzeń lub gdy zależność pomiędzy danymi wejściowymi i akcjami nie jest dobrze zrozumiała. W tej drugiej sytuacji, która dotyczy np. rozpoznawania mowy lub obrazów, najlepsze rezultaty udaje się uzyskiwać za pomocą uczenia maszynowego.
Uczenie maszynowe
Uczenie maszynowe jest blisko związane z procesami optymalizacji. Mając dane wejściowe z bazy, algorytm uczenia maszynowego będzie próbować znaleźć najbardziej odpowiedni sposób sklasyfikowania lub ułożenia ich. Algorytm dopasowywania krzywych, bazujący na technice takiej jak regresja liniowa, uznawany jestza najprostszy możliwy algorytm uczenia maszynowego; używa on podanych punktów danych, by sformułować najlepiej dopasowany wielomian, który następnie wykorzystuje się do wskazywania najbardziej prawdopodobnych wartości wyjściowych. Dopasowywanie krzywych jest jednak stosowne tylko dla systemów o bardzo małej liczbie wymiarów. Prawdziwe aplikacje uczenia maszynowego mogą natomiast radzić sobie ze złożonymi, wielowymiarowymi danymi.
Klasyfikowanie może być bardziej zaawansowane i dzielić dane na grupy. Typowe algorytmy bazują na centroidach, ale w uczeniu maszynowym stosuje się też wiele innych rodzajów klasyfikacji. System bazujący na centroidach wykorzystuje odległości geometryczne pomiędzy punktami danych by określić, czy pasują one do jednej grupy czy innej. Analiza tego typu często jest procesem iteracyjnym. Stosowane są różne kryteria by określić, gdzie tworzą się granice pomiędzy grupami i jak blisko siebie znajdują się punkty danych, zakwalifikowane do tej samej grupy. Technika ta jest skuteczna w odkrywaniu i prezentowaniu wzorów w danych, które mogłyby umknąć ekspertom z danej dziedziny. Innym sposobem na dzielenie danych na klasy jest maszyna wektorów nośnych (SVM – Support Vector Machine). Dzieli ona wielowymiarowe dane na klasy wzdłuż hiperpłaszczyzn, tworzonych z wykorzystaniem technik optymalizacyjnych.
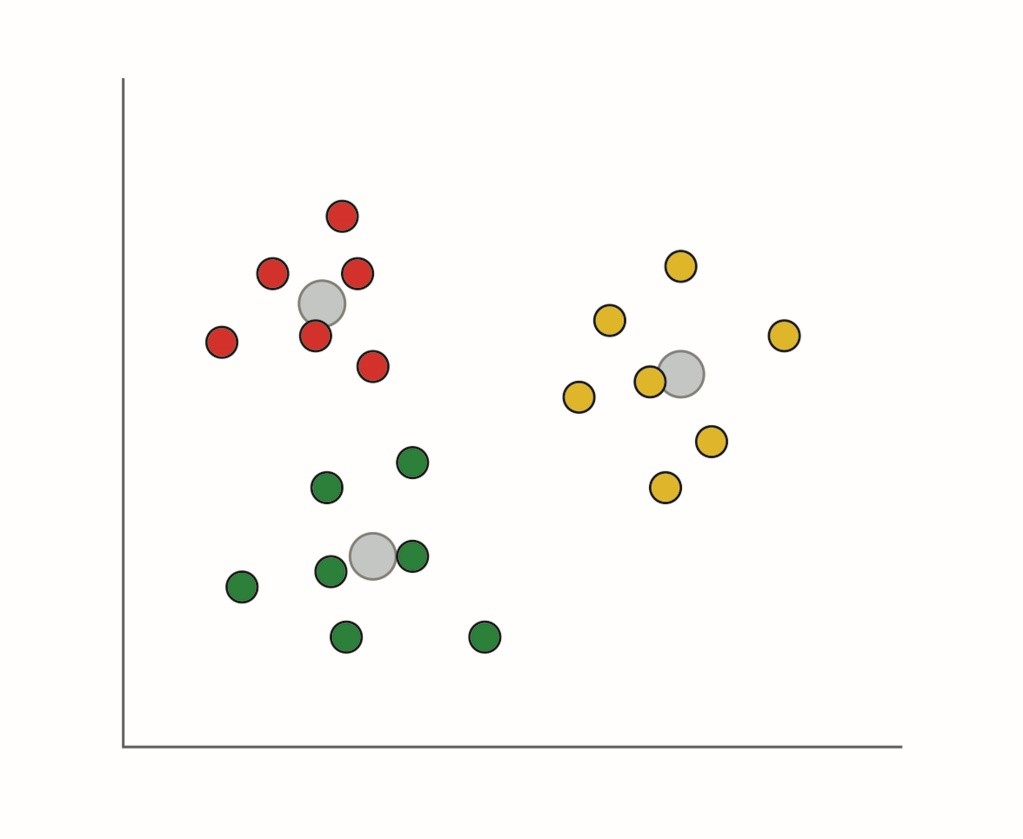 Ilustracja 1. Grupowanie bazuje na mechanizmach takich jak pomiar odległości od najbliższego centroidu, celem podzielenia danych
Ilustracja 1. Grupowanie bazuje na mechanizmach takich jak pomiar odległości od najbliższego centroidu, celem podzielenia danych
Drzewo decyzyjne pozwala na wykorzystanie pogrupowanych danych w bazie zasad i umożliwia algorytmowi AI przechodzenie przez wprowadzane dane, by określić odpowiedź. Każda gałąź w drzewie można określić poprzez analizę grupującą wprowadzanych danych. Przykładowo, system może zachowywać się inaczej powyżej pewnej temperatury. Wtedy odczyt ciśnienia, który normalnie byłby akceptowalny, w tym przypadku pomoże zauważyć problem. Drzewo decyzyjne może wykorzystywać te kombinacje warunków by znaleźć najbardziej odpowiedni zestaw zasad dla danej sytuacji.
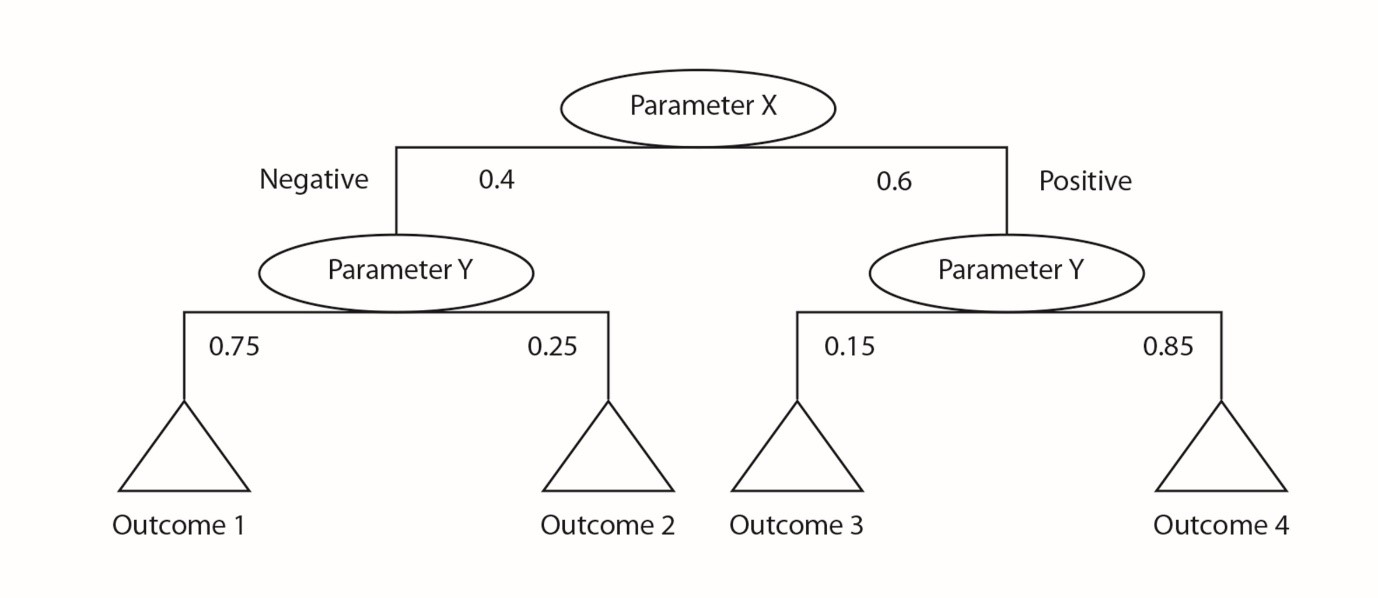 Ilustracja 2. Drzewo decyzyjne stanowi sposób na usystematyzowanie danych. Bazuje na zasadach wynikających z klasyfikacji i na powiązanym z nią prawdopodobieństwem różnych skutków
Ilustracja 2. Drzewo decyzyjne stanowi sposób na usystematyzowanie danych. Bazuje na zasadach wynikających z klasyfikacji i na powiązanym z nią prawdopodobieństwem różnych skutków
AI na systemach wbudowanych
Głębokie sieci neuronowe zazwyczaj wymagają wysoce wydajnego sprzętu, by mogły pracować w czasie rzeczywistym. Istnieją jednak prostsze struktury, takie jak sieci antagonistyczne (Adversarial Neural Networks). Są one z powodzeniem implementowane w mobilnych robotach, pracujących z 32-bitowymi lub 64-bitowymi procesorami. Kluczowe zalety głębokich sieci neuronowych leżą w dużej liczbie warstw, tworzących ich konstrukcję. Taka struktura pozwala neuronom na realizowanie połączeń pomiędzy elementami wielowymiarowych danych. Dane mogą być silnie rozdzielone w przestrzeni i czasie, ale pomiędzy nimi występują ważne zależności, odkrywane podczas procesu uczenia sieci.
Podobnie jak duża złożoność obliczeniowa, wadą głębokich sieci neuronowych jest też ogromna ilość danych, potrzebnych do ich wytrenowania. To dlatego inne algorytmy, takie jak bazujące na procesach gaussowskich, są badane przez naukowców zajmujących się sztuczną inteligencją. Metody te bazują na analizie probabilistycznej danych, w celu budowy modeli, które będą pracować podobnie jak sieci neuronowe. Potrzebują jednak znacznie mniejszej ilości danych trenujących. Jednakże w krótkiej perspektywie sukces głębokich sieci neuronowych czyni je głównym kandydatem do mierzenia się ze złożonymi, wielowymiarowymi danymi wejściowymi. Takimi typami danych są obrazy, materiały wideo, strumienie audio czy ciągłe dane z procesów przemysłowych.
Jedną z opcji jest zastosowanie prostego algorytmu sztucznej inteligencji pracującego w urządzeniu wbudowanym. Wyszukuje on tylko nietypowe zdarzenia w danych wejściowych. Następnie przekazuje odpowiedni pakiet danych do zewnętrznych serwerów w chmurze, by te dokładniej przeanalizowały informacje, co pozwala na udzielenie precyzyjnych odpowiedzi. Taki podział mógłby pomóc utrzymać system pracujący w czasie rzeczywistym i ograniczyć ilość danych, koniecznych do transmisji na długie dystanse. Również może zapewnić ciągłą pracę nawet w przypadku chwilowych problemów z działaniem sieci. Jeśli połączenie z Internetem zostałoby zerwane, system wbudowany mógłby zapisywać podejrzane dane w lokalnej pamięci. Dzieje się tak aż do momentu, gdy powstanie kolejna okazja, by przekazać je do analizy w chmurze.
Dostawcy AI
Amazon Web Services (AWS) i IBM firmy, które już teraz oferują klientom usługi sztucznej inteligencji w chmurze. AWS oferuje dostęp do platform sprzętowych, użytecznych dla uczenia maszynowego. Są to m.in. uniwersalne serwery, akceleratory graficzne i systemy z układami FPGA. Głębokie sieci neuronowe, pracujące w chmurze, można budować z użyciem środowisk open-source, takich jak Caffe i Tensorflow. Są one powszechnie stosowane przez profesjonalistów implementujące sztuczną inteligencję.
IBM przygotował bezpośrednie interfejsy do swojej platformy sztucznej inteligencji Watson. Można się z nią komunikować z poziomu takiego sprzętu, jak Raspberry Pi. Dzięki temu łatwo jest prototypować aplikacje uczenia maszynowego, zanim podejmie się decyzje o finalnej architekturze. Podobnie ARM oferuje zbliżony interfejs do platformy Watson za pomocą środowiska mbed IoT.
Sztuczna inteligencja może wydawać się pieśnią przyszłości w technologiach komputerowych. Tym niemniej dostępne są już wysoce-wydajne, a jednocześnie niedrogie płytki, takich jak Raspberry Pi oraz usługi uczenia maszynowego w chmurze. Sprawia to, że projektanci mają bezpośredni i bardzo łatwy dostęp do pełnego wyboru algorytmów uczenia maszynowego, które opracowano w ciągu ostatnich kilku dekad. Cały czas wymyślane są coraz bardziej wyrafinowane techniki. Dodatkowo połączenie przetwarzania na płytce komputerowej oraz w chmurze stanowi dla projektantów doskonały zestaw narzędzi. Dzięki niemu mogą oni tworzyć najbardziej inteligentne rozwiązania, jakie można przygotować.
 Fotowoltaika perowskitowa: od wydajności laboratoryjnej do masowej komercjalizacji
Fotowoltaika perowskitowa: od wydajności laboratoryjnej do masowej komercjalizacji  Czy kamery termowizyjne pokazują nam całą prawdę?
Czy kamery termowizyjne pokazują nam całą prawdę?  Generowanie ujemnego napięcia odniesienia – eksperymenty z zestawem ADALM2000
Generowanie ujemnego napięcia odniesienia – eksperymenty z zestawem ADALM2000 

![O konkursie organizowanym przez firmę TRUMPF Huettinger i polskie uczelnie techniczne opowiada Alicja Peresada i prof. Jacek Rąbkowski oraz kilkoro nagrodzonych dyplomantów: mgr inż. Jakub Dobosz, inż. Maja Zielińska, dr inż. Jakub Kołodziej, dr inż Weronika Hryniewska-Guzik i dr inż. Grzegorz Bartyzel. Zapraszamy do obejrzenia filmu! [materiał redakcyjny]](https://mikrokontroler.pl/wp-content/uploads/2026/07/TRUMPF-czolowka.png "https://www.youtube.com/watch?v=XkeyLmtLfxo")



