





Intel oraz Instytut Weizmanna przyspieszają sztuczną inteligencję dzięki dekodowaniu spekulatywnemu
Nowa metoda obsługi algorytmów akceleracji sztucznej inteligencji zapewnia do 2,8 razy szybsze wnioskowanie LLM.

Podczas Międzynarodowej Konferencji w Vancouver na temat Uczenia Maszynowego (ICML) naukowcy z Intel Labs i Instytutu Nauki Weizmanna zaprezentowali znaczący postęp w dekodowaniu spekulatywnym. Nowa technika umożliwia każdemu małemu modelowi „szkicowemu” przyspieszenie dowolnego dużego modelu językowego (LLM), niezależnie od różnic w słownictwie.
– Rozwiązaliśmy podstawową nieefektywność generatywnej sztucznej inteligencji. Nasze badania pokazują, jak przekształcić akcelerację spekulatywną w uniwersalne narzędzie. To nie jest tylko teoretyczne ulepszenie; są to praktyczne narzędzia, które już dziś pomagają programistom tworzyć szybsze i inteligentniejsze aplikacje – powiedział Oren Pereg, starszy badacz, Natural Language Processing Group, Intel Labs.
Dekodowanie spekulatywne to technika optymalizacji wnioskowania, zaprojektowana w celu przyspieszenia i zwiększenia wydajności mechanizmów LLM bez uszczerbku dla dokładności. Działa ona poprzez parowanie małego, szybkiego modelu z większym, bardziej dokładnym, tworząc „pracę zespołową” między modelami.
Jak działa dekodowanie spekulatywne?
Naukowcy rozważali pytanie dla modelu AI: „Jaka jest stolica Francji…”. Tradycyjny LLM generuje każde słowo krok po kroku. Najpierw „Paryż”, potem „słynne”, potem „miasto” i tak dalej, zużywając znaczne zasoby na każdym kroku. Dzięki dekodowaniu spekulatywnemu mały model asystenta szybko tworzy pełną frazę „Paryż, słynne miasto…”. Następnie duży model weryfikuje sekwencję. To znacznie zmniejsza liczbę cykli obliczeniowych na token wyjściowy.
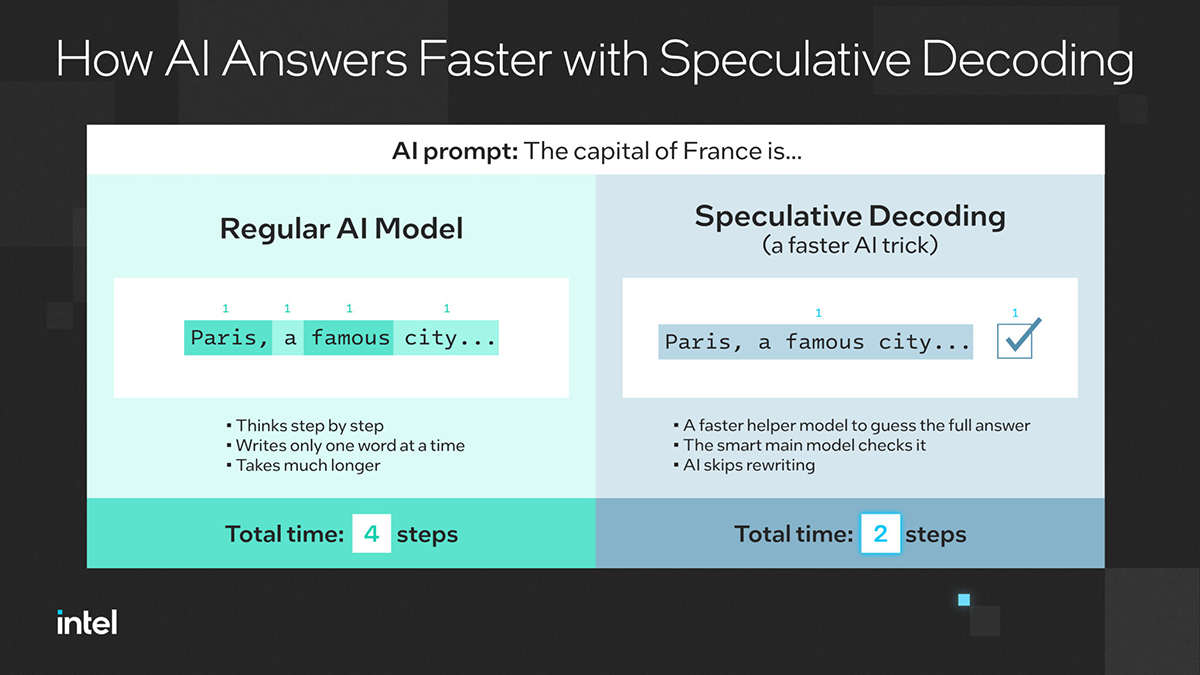
Dlaczego to ma znaczenie? Uniwersalna metoda opracowana przez firmę Intel i Instytut Weizmanna usuwa ograniczenia związane ze współdzielonymi słownikami lub wspólnie trenowanymi rodzinami modeli, czyniąc dekodowanie spekulatywne praktycznym w heterogenicznych modelach. Zapewnia wzrost wydajności nawet o 2,8x szybsze wnioskowanie bez utraty jakości wyjściowej. [1] Działa również na modelach pochodzących od różnych programistów i ekosystemów, dzięki czemu jest niezależny od dostawcy oraz gotowy na open source dzięki integracji z biblioteką Hugging Face Transformers.
W rozdrobnionym krajobrazie sztucznej inteligencji ten spekulacyjny przełom w dekodowaniu promuje otwartość, interoperacyjność i opłacalne wdrażanie od chmury po brzeg sieci. Deweloperzy, przedsiębiorstwa i badacze mogą teraz mieszać i dopasowywać modele do swoich potrzeb w zakresie wydajności i ograniczeń sprzętowych.
– Ta praca usuwa główną barierę techniczną, aby generatywna sztuczna inteligencja była szybsza i tańsza. Nasze algorytmy odblokowują najnowocześniejsze przyspieszenia, które wcześniej były dostępne tylko dla organizacji, które trenują własne małe modele szkiców – powiedział Nadav Timor, doktorant w grupie badawczej profesora Davida Harela w Instytucie Weizmanna.
Artykuł badawczy wprowadza trzy nowe algorytmy, które oddzielają kodowanie spekulatywne od wyrównywania słownictwa. Otwiera to drzwi do elastycznego wdrażania LLM z programistami łączącymi dowolny mały model roboczy z dowolnym dużym modelem w celu optymalizacji szybkości wnioskowania i kosztów na różnych platformach.
Badania nie są tylko teoretyczne. Algorytmy zostały już zintegrowane z biblioteką open source Hugging Face Transformers, z której korzystają miliony programistów. Dzięki tej integracji zaawansowana akceleracja LLM jest dostępna od razu po wyjęciu z pudełka, bez potrzeby tworzenia niestandardowego kodu.
Źródło: materiały prasowe
 Ile energii potrzebuje ChatGPT do obsługi ponad 365 mld zapytań użytkowników rocznie?
Ile energii potrzebuje ChatGPT do obsługi ponad 365 mld zapytań użytkowników rocznie?  Globalny rynek LLM w robotyce przekroczy 100 mld USD do 2028 r.
Globalny rynek LLM w robotyce przekroczy 100 mld USD do 2028 r.  Bielik – Nowy, polski model LLM
Bielik – Nowy, polski model LLM  Łukasiewicz EMAG zmienia nazwę na Łukasiewicz-AI: będzie jednym z największych ośrodków badawczych sztucznej inteligencji i cyberbezpieczeństwa w Polsce
Łukasiewicz EMAG zmienia nazwę na Łukasiewicz-AI: będzie jednym z największych ośrodków badawczych sztucznej inteligencji i cyberbezpieczeństwa w Polsce 






