





Freescale Coldfire i Kinetis od środka

Nowe rodziny mikrokontrolerów firmy Freescale Semiconductors, produkowane w technologii 90nm, są zbudowane w oparciu o rdzenie ColdFire V1 i ARM Cortex-M4. Każdy z nich ma cechy, które czynią go dobrym wyborem dla wielu zastosowań w aplikacjach w systemach wbudowanych.
Rdzeń ColdFire wersji 1 (V1)
Celem przy projektowaniu 32-bitowego rdzenia ColdFire V1, przeznaczonego do prostszych, bardziej podstawowych zastosowań, była minimalizacja jego gabarytów oraz zużycia mocy. Jest on uproszczoną wersją rdzenia ColdFire V2 i jest wyposażony w ulepszone mechanizmy obsługi operandów bajtowych oraz słów 16-bitowych, zachowując wszystkie tryby adresowania i definicje instrukcji architektury ColdFire. Rdzeń ten implementuje zestaw instrukcji ColdFire Revision C. Na rysunku 1 pokazano model programowania, zawierający:
- 16 rejestrów 32-bitowych ogólnego przeznaczenia (8 dla danych, D[0-7] i 8 adresowych, A[0-7]),
- 32-bitowy licznik programu (program counter, PC),
- 8-bitowy rejestr stanu (condition code register, CCR).
Model programowy procesora (Instruction Set Architecture) definiuje operacje zmiennej długości, w których instrukcje mogą mieć 16, 32 lub 48 bitów i udostępnia potężny zestaw trybów adresowania pamięci danych. Obsługiwane są 1-, 8-, 16- i 32-bitowe liczby całkowite, a wśród operacji odwołujących się do pamięci, oprócz pobrania i zapisu, można znaleźć operacje typu embedded load, które pobierają operand z pamięci i od razu go przetwarzają oraz operacje wykonujące przesunięcia danych wewnątrz pamięci.
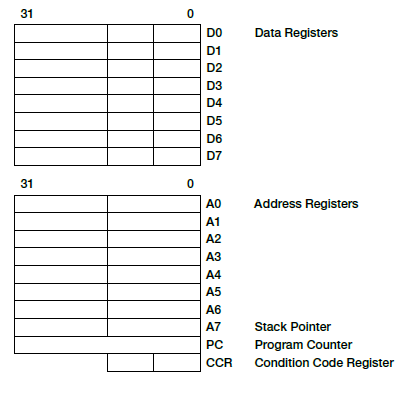
Rys. 1. Model programowania rdzeni rodziny ColdFire dla liczb całkowitych
Rozszerzona jednostka MAC (Enhanced Multiply-Accumulate, EMAC), w którą wyposażone są rodziny MCF51Qx/Jx, obsługuje 16- i 32-bitowe liczby niecałkowite ze znakiem, złożone instrukcje typu MAC+MOVE, cykliczne adresowanie kolejek i zawiera cztery 48-bitowe akumulatory.
Rdzeń ColdFire V1 ma też zaimplementowane typowe instrukcje koprocesorów oraz jest wyposażony w sprzętowy interfejs przyspieszający operacje na poziomie instrukcji lub funkcji. Przykładem może być jednostka Cryptographic Acceleration Unity (CAU), która daje znaczne polepszenie wydajności przy implementacji wielu typowych algorytmów używanych do zabezpieczeń, takich jak: DES, AES, SHA1, SHA-256 i MD5. Interfejs koprocesora zapewnia akcelerator, w którym CPU pobiera operandy i wysyła polecenia do modułu sprzętowego.
Jak we wszystkich implementacjach architektury ColdFire, w wersji 1 wykorzystywany jest dwustopniowy potok pobierania instrukcji (Instruction Fetch Pipeline, IFP) i dwustopniowy potok wykonywania instrukcji (Operand Execution Pipeline, OEP), co zapewnia prawidłową sprzętową obsługę zestawu instrukcji o zmiennej długości. Interfejsem między rdzeniem a układem typu System-on-Chip jest pojedyncza, 32-bitowa magistrala AMBA™ typu AHB (AMBA™ High-performance Bus). Interfejsy do pamięci potoków IFP i OEP są multipleksowane i mapowane wprost na dwustopniową (faza adresowa i faza danych), potokową magistralę AHB.
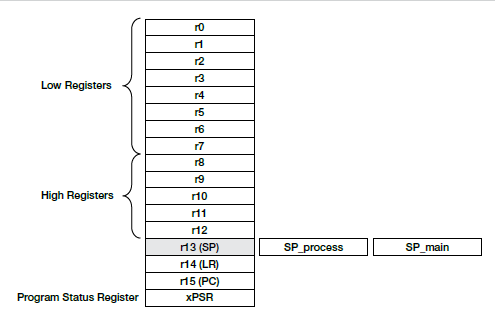
Rys. 2. Model programowania rdzeni ARM® Cortex™-Mx (rejestry)
 Grzegorz Kamiński: Dlaczego powstały tranzystory FinFET i GAAFET?
Grzegorz Kamiński: Dlaczego powstały tranzystory FinFET i GAAFET?  Google stawia na fuzję jądrową. AI potrzebuje coraz więcej energii
Google stawia na fuzję jądrową. AI potrzebuje coraz więcej energii  Fotowoltaika perowskitowa: od wydajności laboratoryjnej do masowej komercjalizacji
Fotowoltaika perowskitowa: od wydajności laboratoryjnej do masowej komercjalizacji 

![O konkursie organizowanym przez firmę TRUMPF Huettinger i polskie uczelnie techniczne opowiada Alicja Peresada i prof. Jacek Rąbkowski oraz kilkoro nagrodzonych dyplomantów: mgr inż. Jakub Dobosz, inż. Maja Zielińska, dr inż. Jakub Kołodziej, dr inż Weronika Hryniewska-Guzik i dr inż. Grzegorz Bartyzel. Zapraszamy do obejrzenia filmu! [materiał redakcyjny]](https://mikrokontroler.pl/wp-content/uploads/2026/07/TRUMPF-czolowka.png "https://www.youtube.com/watch?v=XkeyLmtLfxo")



