





Biblioteka DSP dla mikrokontrolerów LPC1700 i LPC1300 firmy NXP
Mnożenie wektora przez stałą
Każdy element wektora jest mnożony przez stałą. Wzór na mnożenie wektora przez stałą:
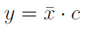
Prototyp funkcji VectMulConst16:
void vF_dspl_vectmulconst16(short int *psi_y, short int *psi_x, short int si_c, int i_VectorLen);
Prototyp funkcji VectMulConst32:
void vF_dspl_vectmulconst32(int *pi_y, int *pi_x, int i_c, int i_VectorLen);
Wydajność obliczeń przedstawiono w tabeli 7.
Tab. 7. Mnożenie wektora przez stałą
| Mnożenie wektora | Mnożnik zegara pamięci 1 | Mnożnik zegara pamięci 2 | Mnożnik zegara pamięci 3 | |||
| przez stałą | (20 MHz maks.) | (40 MHz maks.) | (60 MHz maks.) | |||
| Cykle | Czas (μs) | Cykle | Czas (μs) | Cykle | Czas (μs) | |
| 16 bitów | 243 | 12,150 | 247 | 6,175 | 252 | 4,200 |
| 32 bitów | 274 | 13,700 | 277 | 6,925 | 280 | 4,667 |
| Mnożenie wektora | Mnożnik zegara pamięci 4 | Mnożnik zegara pamięci 5 | Mnożnik zegara pamięci 6 | |||
| przez stałą | (80 MHz maks.) | (100 MHz maks.) | (120 MHz maks.) | |||
| Cykle | Czas (μs) | Cykle | Czas (μs) | Cykle | Czas (μs) | |
| 16 bitów | 257 | 3,213 | 264 | 2,640 | 264 | 2,200 |
| 32 bitów | 283 | 3,538 | 286 | 2,860 | 286 | 2,383 |
Suma kwadratów
Wzór na sumę kwadratów wartości wektora:
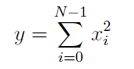
Prototyp funkcji VectSumSquares16:
int iF_dspl_vectsumofsquares16(short int *psi_x, int i_VectorLen);
Prototyp funkcji VectSumSquares32 function prototype
int iF_dspl_vectsumofsquares32(int *pi_x, int i_VectorLen);
Wydajność obliczeń przedstawiono w tabeli 8.
Tab. 8. Suma kwadratów
| Suma kwadratów | Mnożnik zegara pamięci 1 | Mnożnik zegara pamięci 2 | Mnożnik zegara pamięci 3 | |||
| wartości wektora | (20 MHz maks.) | (40 MHz maks.) | (60 MHz maks.) | |||
| Cykle | Czas (μs) | Cykle | Czas (μs) | Cykle | Czas (μs) | |
| 16 bitów | 242 | 12,100 | 244 | 6,100 | 247 | 4,117 |
| 32 bitów | 242 | 12,100 | 245 | 6,125 | 249 | 4,150 |
| Suma kwadratów | Mnożnik zegara pamięci 4 | Mnożnik zegara pamięci 5 | Mnożnik zegara pamięci 6 | |||
| wartości wektora | (80 MHz maks.) | (100 MHz maks.) | (120 MHz maks.) | |||
| Cykle | Czas (μs) | Cykle | Czas (μs) | Cykle | Czas (μs) | |
| 16 bitów | 250 | 3,125 | 254 | 2,540 | 254 | 2,117 |
| 32 bitów | 254 | 3,175 | 259 | 2,590 | 259 | 2,158 |
Filtr o skończonej odpowiedzi impulsowej (FIR)
W przeciwieństwie do procesorów sygnałowych, Cortex-M3 nie może wykonywać operacji odczytu równolegle z operacjami ALU, zatem każdy cykl wczytywania danych jest cyklem, podczas którego nie można dokonywać obliczeń arytmetycznych na potrzeby filtru. Funkcje FIR są w istocie długimi sekwencjami operacji mnożenia i dodawania (MAC), w których wynik jest rezultatem sumowania wielu współczynników mnożonych przez wartość wejściową.
Aby zmaksymalizować wydajność filtru FIR w procesorze Cortex-M3, zastosowano tak zwany algorytm „ block-FIR ”. Algorytm ten redukuje liczbę odwołań do pamięci poprzez obliczanie kilku próbek wyjściowych w każdym obiegu pętli. W ten sposób dane wejściowe i współczynniki mogą zostać użyte ponownie przed doczytaniem kolejnych wartości z pamięci.
Wzór opisujący filtr:
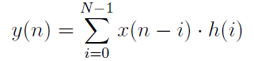
Odwoływanie się do filtru:
typedef struct
{
int *pi_Coeff;
int NTaps;
}tS_blockfir32_Coeff;
void vF_dspl_blockfir32(int *pi_y, int *pi_x, tS_blockfir32_Coeff *pS_Coeff, int i_nsamples);
Uwaga. Liczba i_nsamples musi być wielokrotnością 4.
 Jak model Industry 5.0 wspiera zrównoważony rozwój w polskim przemyśle
Jak model Industry 5.0 wspiera zrównoważony rozwój w polskim przemyśle  Daniel Brzeziński z Rochester Electronics opowiada jak skutecznie zarządzać przestrzałością w branży półprzewodników
Daniel Brzeziński z Rochester Electronics opowiada jak skutecznie zarządzać przestrzałością w branży półprzewodników  AI podważa zasady, które rządziły branżą przez dekady. Moc obliczeniowa staje się nową walutą technologii
AI podważa zasady, które rządziły branżą przez dekady. Moc obliczeniowa staje się nową walutą technologii 






