





Cortex-M3 vs Cortex-M4 – czym się różnią?
Rdzeń ARM Cortex-M4 to najnowsze opracowanie „mikrokontrolerowe” firmy ARM, przeznaczone dla aplikacji cyfrowych układów regulacji i sterowania, którym stawia się wymagania, aby były wydajne i miały łatwe w użyciu funkcje sterowania i przetwarzania sygnałów w aplikacjach mikrokontrolerów.
Połączenie wysokiej wydajności przetwarzania sygnałów z niskim poborem mocy, niewielkim kosztem implementacji i łatwością użycia sprawia, że rdzenie Cortex-M spełniają nowoczesne wymagania stawiane rozwiązaniom układowym do sterowania silnikami elektrycznymi, urządzeniach samochodowych, w systemach zarządzania i konwersji energii, przetwarzania dźwięku i automatyki. Rdzeń Cortex-M4 jest standardowo wyposażony w jednostkę obliczeniową MAC (Multiply and ACcumulate) do wykonywania operacji mnożenia i sumowania w jednym cyklu pracy, wykonuje instrukcje SIMD (Single Instruction, Multiple Data) zoptymalizowanych operacji na wielu danych, instrukcje arytmetyki nasyceniowej (saturating arithmetic), a opcjonalnie może być wyposażony w zmiennoprzecinkowy koprocesor obliczeniowy FPU (Floating-Point Unit) do wykonywania operacji na liczbach zmiennoprzecinkowych pojedynczej precyzji.
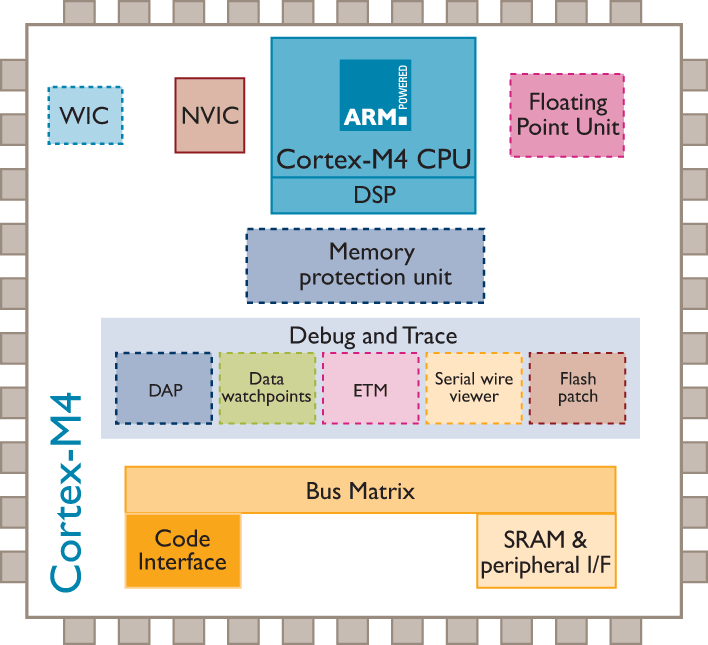
Rys. 1. Schemat blokowy rdzenia Cortex-M4/Cortex-M4F (po zastosowaniu opcjonalnego koprocesora FPU)
Schemat blokowy rdzenia Cortex-M4 pokazano na rysunku 1.
Zalety rdzenia Cortex-M4
Rdzeń Cortex-M4, podobnie jak Cortex-M3, charakteryzuje się prędkością wykonywania standardowych programów o wartości 1,25 MIPS/MHz (milionów instrukcji na sekundę)/MHz (Dhrystone 2.1), ale ze względu na wbudowany blok sprzętowy MAC rdzeń Cortex-M4 zapewnia lepszą wydajność cyfrowego przetwarzania sygnałów (DSP). MAC jest jednostką wykonującą w jednym cyklu pracy operacje mnożenia i sumowania jednocześnie na liczbach 16 i 32-bitowych, a zestaw instrukcji SIMD (Single Instruction Multiple Data) umożliwia wykonywanie w jednym cyklu pracy operacji na dwóch liczbach 16-bitowych i czterech liczbach 8-bitowych.
Opcjonalny koprocesor FPU w rdzeniach Cortex-M4 jest implementacją wariantu pojedynczej precyzji układu rozszerzenia zmiennoprzecinkowego Floating-Point Extension (FPv4-SP) architektury ARMv7-M. Zapewnia ona obliczenia na liczbach zmiennoprzecinkowych, spełniając normy ANSI/IEEE STD 754-2008 oraz normy IEEE dotyczące obliczeń na liczbach zmiennoprzecinkowych (Standard for Binary Arithmetic Floating-Point, IEEE 754).
Czego więcej ma Cortex-M4
MAC
Wbudowana w rdzeń Cortex-M4 32-bitowa jednostka obliczeniowa MAC (Multiply and ACcumulate) w jednym cyklu pracy może wykonać:
- jedną operację mnożenia dwóch liczb 32-bitowych i następnie sumowania wyniku z liczbą 64-bitową, dając w rezultacie liczbę 64-bitową: 32×32+64->64
- dwie operacje mnożenia dwóch liczb 16-bitowych: 16×16.
Jednostka MAC powoduje, że cyfrowe przetwarzanie sygnałów jest bardziej efektywne i zmniejsza zużycie zasobów rdzenia, co wynika z udostępnianych przez MAC funkcjonalności:
- wielu instrukcji operacji mnożenia i sumowania,
- sprzętowego mnożenia liczb 16- lub 32-bitowych oraz sumowania liczb 32- lub 64-bitowych,
- wykonywania tych instrukcji w jednym cyklu pracy.
| Przewaga w DSP
Na rysunku poniżej zestawiono porównanie względnych wydajności rdzeni Cortex-M3 i Cortex-M4, taktowanych sygnałem zegarowym o tej samej częstotliwości, realizujących algorytmy DSP i obliczenia zmiennoprzecinkowe. Oś y reprezentuje względną liczbę cykli wykonania danej funkcji: im mniejsza liczba cykli, tym większa wydajność.
Complex FFT – FFT na liczbach zespolonych |

SIMD
Rdzeń Cortex-M4 obsługuje instrukcje SIMD (Single Instruction, Multiple Data), co pozwala optymalizować operacje wykowywane na wielu danych jednocześnie. W skład zestawu instrukcji SIMD wchodzą niektóre instrukcje DSP, do wykonywania takich operacji jak dodawanie, odejmowanie, mnożenie, mnożenie i sumowanie, które są wykorzystywane do implementacji powszechnie stosowanych operacji cyfrowego przetwarzania sygnałów, w tym filtrowania sygnałów cyfrowych za pomocą filtrów o skończonej odpowiedzi impulsowej FIR (Finite Impulse Response) lub o nieskończonej odpowiedzi impulsowej IIR (Infinite Impulse Response), obliczania szybkiej transformaty Fouriera FFT (Fast Fourier Transform) na liczbach zespolonych, obliczania parametrów regulatorów proporcjonalno-całkująco-różniczkujących PID (Proportional–Integral–Derivative) oraz sumowania, odejmowania i mnożenia macierzy.
Instrukcje SIMD umożliwiają (w jednym takcie zegara):
- wykonanie czterech operacji równoległych: dodawania lub odejmowania liczb 8-bitowych,
- wykonanie dwóch operacji równoległych: dodawania lub odejmowania liczb 16-bitowych.
 Fotowoltaika perowskitowa: od wydajności laboratoryjnej do masowej komercjalizacji
Fotowoltaika perowskitowa: od wydajności laboratoryjnej do masowej komercjalizacji  Czy kamery termowizyjne pokazują nam całą prawdę?
Czy kamery termowizyjne pokazują nam całą prawdę?  Generowanie ujemnego napięcia odniesienia – eksperymenty z zestawem ADALM2000
Generowanie ujemnego napięcia odniesienia – eksperymenty z zestawem ADALM2000 

![O konkursie organizowanym przez firmę TRUMPF Huettinger i polskie uczelnie techniczne opowiada Alicja Peresada i prof. Jacek Rąbkowski oraz kilkoro nagrodzonych dyplomantów: mgr inż. Jakub Dobosz, inż. Maja Zielińska, dr inż. Jakub Kołodziej, dr inż Weronika Hryniewska-Guzik i dr inż. Grzegorz Bartyzel. Zapraszamy do obejrzenia filmu! [materiał redakcyjny]](https://mikrokontroler.pl/wp-content/uploads/2026/07/TRUMPF-czolowka.png "https://www.youtube.com/watch?v=XkeyLmtLfxo")

![Szymon Robak oprowadza po katowickim Laboratorium Badań Kompatybilności Elektromagnetycznej w Sieć Badawcza Łukasiewicz - Instytucie Sztucznej Inteligencji i Cyberbezpieczeństwa. Zapraszamy na film! [materiał redakcyjny]](https://mikrokontroler.pl/wp-content/uploads/2026/06/Szymon-Robak-tytulowe.png "https://www.youtube.com/watch?v=gHcP8AajoN4")

