





Migracja z Cortex-M3 do Cortex-M4
MPU
Tak samo jak w przypadku Cortex-M3, MPU w Cortex-M4 jest opcjonalną jednostką ochrony pamięci. Rdzeń obsługuje standardowy model architektury systemu ARMv7 z ochroną pamięci. Z jednostki MPU można skorzystać do egzekwowania zasad uprawnień/dostępu i realizacji odrębnych procesów. Jednostka MPU zapewnia pełną obsługę:
- chronionych regionów,
- chronionych regionów nakładających się na siebie, z rosnącym priorytetem regionu, gdzie:
- 7 = najwyższy priorytet
- 0 = najniższy priorytet
- uprawnień dostępu,
- eksportu atrybutów pamięci do systemu.
Możliwości cyfrowego przetwarzania sygnałów
Podane poniżej rysunki ilustrują względne porównania wydajności pomiędzy Cortex-M3 i Cortex-M4 w odniesieniu do możliwości cyfrowego przetwarzania sygnałów, gdzie oba rdzenie działają z tą samą prędkością.
W poniższych rysunkach, oś y reprezentuje względną liczbę cykli wykonania danej funkcji. Odpowiednio, im mniejsza liczba cykli, tym lepsza wydajność. Ponieważ Cortex-M3 jest traktowany referencyjnie, wydajność Cortex-M4 jest obliczana jako odwrotność jego względnej liczby cykli. Na przykład, dla funkcji PID, liczba cykli Cortex-M4 wynosi około 0.7 x w porównaniu z Cortex-M3, a zatem względna wydajność wynosi 1/0.7 lub 1.4x.

Rys. 5. Liczba cykli wykonywania 16-bitowych funkcji przez Cortex-M
Complex FFT – FFT zespolone
Matrix Addition – Dodawanie macierzy
Matrix Subtraction – Odejmowanie macierzy
Matrix Multiplication – Mnożenie macierzy
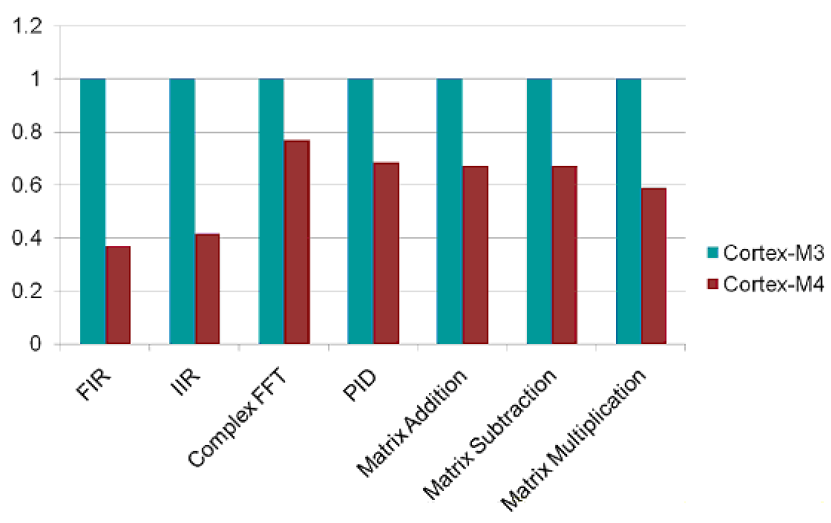
Rys. 6. Liczba cykli wykonywania 32-bitowych funkcji przez Cortex-M
Complex FFT – FFT zespolone
Matrix Addition – Dodawanie macierzy
Matrix Subtraction – Odejmowanie macierzy
Matrix Multiplication – Mnożenie macierzy
Jest oczywiste, że Cortex-M4 ma dużą przewagę w zakresie cyfrowego przetwarzania sygnałów w porównaniu z Cortex-M3, zarówno dla operacji 16-bitowych, jak i 32-bitowych. Wszystkie instrukcje DSP są wykonywane przez Cortex-M4 w jednym cyklu, podczas gdy Cortex-M3 potrzebuje wielu instrukcji i wielu cykli do wykonania równoważnej funkcji. Przykładowo, dla algorytmu PID, który należy do najbardziej zasobochłonnych wśród operacji DSP, Cortex-M4 zapewnia 1.4 – krotny wzrost wydajności. W innym przykładzie aplikacji, dekodowanie MP3 wymagające szybkości przetwarzania od 20 do 25 MHz z rdzeniem Cortex-M3, wymaga tylko od 10 do 12 MHz z rdzeniem Cortex-M4.
32-bitowa jednostka obliczeniowa MAC
W procesorze Cortex-M4 znajduje się 32-bitowa jednostka obliczeniowa MAC, która dostarcza nowe instrukcje i ma zoptymalizowany układ wykonawczy. W jednym cyklu pracy może wykonać jedną operację mnożenia dwóch liczb 32-bitowych i następnie sumowania wyniku z liczbą 64-bitową dając w rezultacie liczbę 64-bitową: 32×32+64->64, lub dwie operacje mnożenia dwóch liczb 16-bitowych: 16×16. W tabeli 2 podano operacje, które ta jednostka może wykonać.
Tab. 2.
| Operacja | Instrukcja | Liczba cykli |
| 16 x 16 = 32 | SMULBB, SMULBT, SMULTB, SMULTT | 1 |
| 16 x 16 + 32 = 32 | SMLABB, SMLABT, SMLATB, SMLATT | 1 |
| 16 x 16 + 64 = 64 | SMLALBB, SMLALBT, SMLALTB, SMLALTT | 1 |
| 16 x 32 = 32 | SMULWB, SMULWT | 1 |
| (16 x 32) + 32 = 32 | SMLAWB, SMLAWT | 1 |
| (16 x 16) ± (16 x 16) = 32 | SMUAD, SMUADX, SMUSD, SMUSDX | 1 |
| (16 x 16) ± (16 x 16) + 32 = 32 | SMLAD, SMLADX, SMLSD, SMLSDX | 1 |
| (16 x 16) ± (16 x 16) + 64 = 64 | SMLALD, SMLALDX, SMLSLD, SMLSLDX | 1 |
| 32 x 32 = 32 | MUL | 1 |
| 32 ± (32 x 32) = 32 | MLA, MLS | 1 |
| 32 x 32 = 64 | SMULL, UMULL | 1 |
| (32 x 32) + 64 = 64 | SMLAL, UMLAL | 1 |
| (32 x 32) + 32 + 32 = 64 | UMAAL | 1 |
| 2 ± (32 x 32) = 32 (część starsza) | SMMLA, SMMLAR, SMMLS, SMMLSR | 1 |
| (32 x 32) = 32 (część starsza) | SMMUL, SMMULR | 1 |
 Automatyka ATS i SZR – dlaczego nowoczesny zakład produkcyjny nie może polegać wyłącznie na zasilaniu z sieci?
Automatyka ATS i SZR – dlaczego nowoczesny zakład produkcyjny nie może polegać wyłącznie na zasilaniu z sieci?  Rozwój potencjału produkcyjnego Assemblertec dzięki wieloletniej współpracy z PB Technik – historia sukcesu
Rozwój potencjału produkcyjnego Assemblertec dzięki wieloletniej współpracy z PB Technik – historia sukcesu  Przemysł obronny przyciąga coraz więcej inwestorów – Polska ma szansę wykorzystać to do rozwoju eksportu
Przemysł obronny przyciąga coraz więcej inwestorów – Polska ma szansę wykorzystać to do rozwoju eksportu 

![O konkursie organizowanym przez firmę TRUMPF Huettinger i polskie uczelnie techniczne opowiada Alicja Peresada i prof. Jacek Rąbkowski oraz kilkoro nagrodzonych dyplomantów: mgr inż. Jakub Dobosz, inż. Maja Zielińska, dr inż. Jakub Kołodziej, dr inż Weronika Hryniewska-Guzik i dr inż. Grzegorz Bartyzel. Zapraszamy do obejrzenia filmu! [materiał redakcyjny]](https://mikrokontroler.pl/wp-content/uploads/2026/07/TRUMPF-czolowka.png "https://www.youtube.com/watch?v=XkeyLmtLfxo")

![Szymon Robak oprowadza po katowickim Laboratorium Badań Kompatybilności Elektromagnetycznej w Sieć Badawcza Łukasiewicz - Instytucie Sztucznej Inteligencji i Cyberbezpieczeństwa. Zapraszamy na film! [materiał redakcyjny]](https://mikrokontroler.pl/wp-content/uploads/2026/06/Szymon-Robak-tytulowe.png "https://www.youtube.com/watch?v=gHcP8AajoN4")

